はじめに
少し前に早稲田の学生さんとやり取りしていて、お絵描きしたのですが、埋まる前にこちらにも貼り付けて保全しておきたいと思います。以前下記の記事で書いた話の延長です。
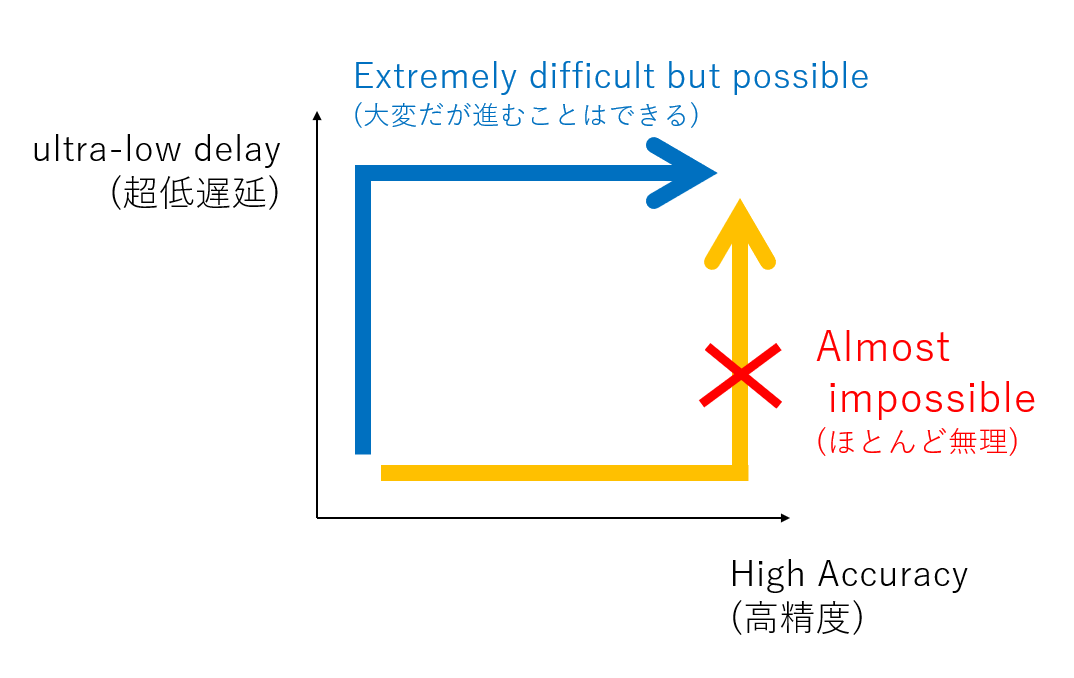
リアルで連続的な情報を使うという事
従来CNNでは、ResNet にせよ YOLO にせよワンショットでの認識ですので、例えばFPGAなりで 1TOPs の計算機で 100fps で計算するなら、基本的には一回の計算が 10GOP 以下のネットを1秒間に百回計算可能です。
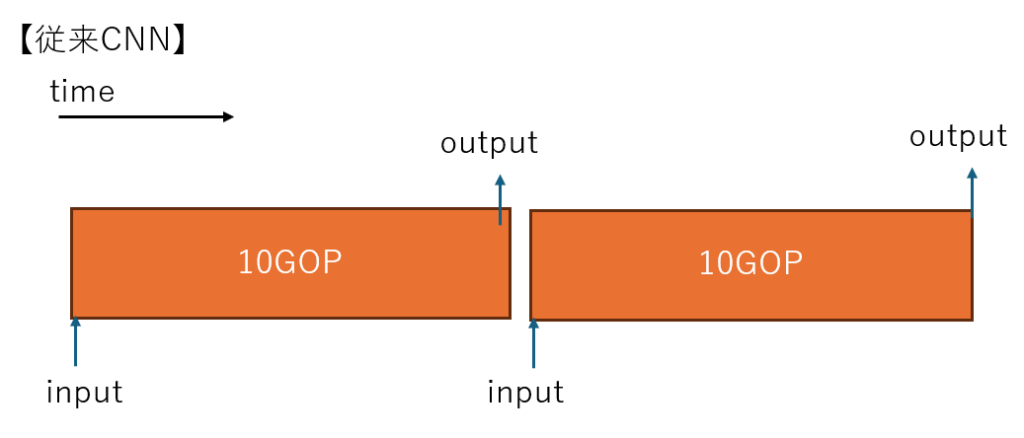
一方で、計算結果を毎回毎回捨ててしまうのはもったいないので「前のフレームの情報も活用しよう」、「連続性を高めるためにフレームレートを上げて、現実世界の変化が小さいうちに更新しよう」、「低遅延で応答性を10倍ぐらいに上げよう」、みたいなことを企むと、1回の演算量が1/10ぐらいのモデルを作って 1000fps ぐらいで計算するのもありでは? という下記のような話になります。

で、仮説として下記のようなことが起こらないか期待するわけです。
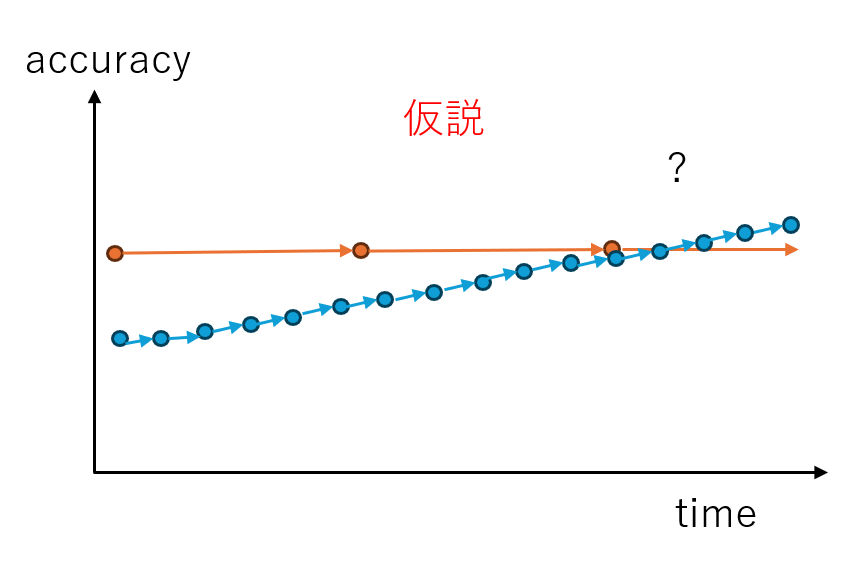
応答性も精度も両方で従来方式の上を行こうという欲張りな狙いです(もちろん学生のテーマとしてはどちらか片方達成するだけでも成果と言えるかと思います)。
前のフレームの計算結果も捨てずに使っているという事は、今の output には過去のすべての計算が活用されているわけですから、outputを作るのに使った演算量は10ms毎に情報をすべて捨て去って再計算している従来モデルより良くなる可能性は秘めているわけです。
目論見として
- 従来CNNより 1/10 の時間で応答する超リアルタイム性
- 最終的に従来より高い精度を出せる可能性
の2点を期待してしまうわけです。
ただし、ご承知の通り、RNNは、データセットの準備も含めて、学習させるのがとても大変なので、なかなか取り組みが難しいところはあるのかなと思っています。
カルマンフィルタ的だという話
で、更新していくネットの形って細かいところはおいておいて、結局は現在時刻の観測値 Xt から推定した値と、1つ前の結果から予測した現在の予測値を、適当な比率(ゲイン)で混合するモデルになるかと思います。
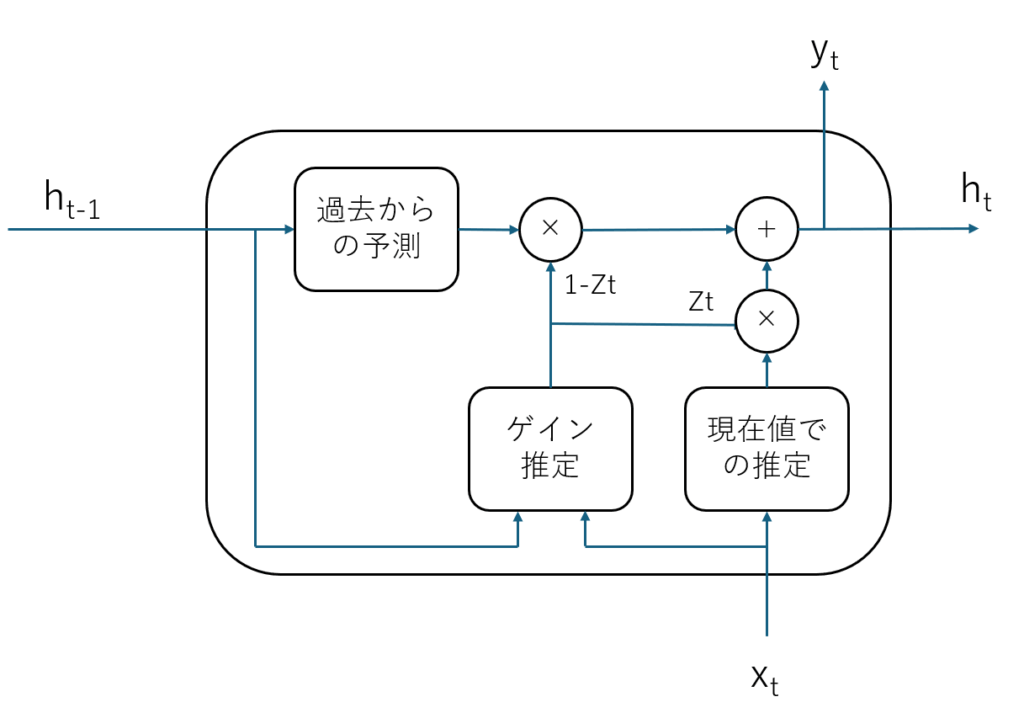
これは、ほぼほぼ GRUの構造そのままなのですが、カルマンフィルタの、それぞれの要素を深層学習で置換しただけとも言えます。
- 観測値から目標を深層学習で推定する(従来のCNNはここだけ)
- 直前の値から現在の値を深層学習で予測する
- カルマンゲインに相当するブレンド率を深層学習で求める
ということをやってるだけな気がしています。
どういうときに効果が出そうか?
以前に、例えばルールベースの世界では、フレームレートをダイナミクスに対して十分上げると、例えば動き探索のようなタスクは性能が突然上がるポイントがあるという話をしました。
1フレームに最大で100ピクセル移動する物体を追跡するには、201×201 の範囲の探索が必要で、40401か所の探索が必要ですが、100倍速いフレームレートでは1フレームに1ピクセルしか移動しなくなるので、3×3の範囲を100回行えばよく、演算量は 900 回の探索のみで、なんとフレームレートを100倍にすると計算量が 45分の1 にむしろ減るという面白いことが起きます。
同じようなことは、RNNでもフレームレートを上げると起こりうる可能性はあるかと思っています。変化量を求めるようなタスクは有意義かもしれません。
またそうでなくとも、動いている物体を100倍のフレームレートの中で撮影すれば、少しづつ視点の違う画像が100枚取れますので、1枚だけで認識するより有利です。さらに照明やカメラのゲインなどの条件を変えながら撮影すれば、100枚の画像の中にさらに情報量を持たせることができます。
場合によっては100枚それぞれで、異なるパラメータに入れ替えて推論を行うこともできるかもしれません。
一方で、あまりに変化のない世界だと、折角100倍の速度で動いても同じ画像が100回入ってくるだけで、さらには同じパラメータで100回計算しても同じ計算を100回するだけで何のメリットもありません。やはり変化のあるダイナミクスを持った世界の観測に適用してこそ効果が期待できるアイデアかとは思います。そのようなシチュエーションを想定して学習の為のデータセットを作っていく必要があるのだと思います。
仮に出来たとしてどう実装するのか
実はこれも割と重要な話でして、仮にハイフレームレートで劇的に効果の出る少ない計算量のRNN的のモデルがPytorch上などで学習できたと仮定しましょう。
しかしながら計算を行うには、データとパラメータを適切に演算器に供給できなければ絵に描いた餅になってしまいます。
演算器をストールさせることなく高密度に駆動するというのは巨大な行列を扱うケースでも十分難しいタスクです。例えば Google の TPU のシストリックアレイなどは有名ですが、こような仕組みを使ってようやく大量の演算器を高い稼働率で演算しています。
一方で、1000fpsのようなハイサンプリングレートで、RNNのような構造を持たせて、細かで複雑なモデルを効率よく計算できる計算機アーキテクチャを考えるのは案外大変なのです。
折角、FPGAに多数のDSPやLUTやSRAMが内蔵されていても、バス帯域の律速などデータ供給回路が律速してしまい結果1%も稼働してなかったとか、稼働率が低いぐらいならまだよくて、どうやっても合成可能な回路にならなくて諦めてしまうなんてこともしばしあるわけです。
この問題に関する解は明確で、初めから計算機のアーキテクチャもセットで設計するということに尽きるかと思います。
この時、当然「どのような計算機アーキテクチャであれば実装可能か?」という部分に勘所を事前にもっておく必要があります。
計算機科学を学んでいる学生さんは少なからず、現代計算機の構成において、ベクトル演算であったり、マルチコアの演算であったり、キャッシュシステムであったり学んではいるはずですが、実際作ってみないと気づけない課題は山ほど出てきますので、少しでもクリティカルな課題に当たるのも避ける意味でもやはりいろいろやってみていろいろ経験を積むという事を早い段階から取り組んでもらうのが重要には思っております。
おわりに
偉そうなことを書いてはおりますが、私自身は最近口だけでほとんど手が動かせていなかったりもします。逆に溜まってしまっているこの手のアイデアの可能性を若手の方々に、また若い視点でいろいろと取り組んでいただけるのは有難いことでもあります。
実際にシステムを組むところまで考えると割と泥臭い作業が山ほどありますので、なかなかAIモデルを考えるだけでは済まないところがありますので、いろんな方々と連携していければと思っております。
後日追記
なんとなくRNNじゃなくて Transformer みたいにワンショットの学習だけで何とかならないのかなどと考えてみましたが、やはり一筋縄ではいかなそうにも思っております。



コメント