はじめに
最近、早稲田の学生さん向けに研究の種になりそうなアイデアを説明する機会も多くなってきました。折角なのでこちらにも少し同じことを備忘録として残していければと思います。
以前、下記のようなことを書いてプチバズったことがあるのですが、同じようなことをAI用のネットワークモデルとして応用できないかという話になります。
計算量と精度の話
まず、どんな計算機も一定時間に使える演算量には上限があります。
1ms でも 10ms でもいいのですが、 例えば 100fps のカメラ入力から10ms 毎に新しい画像を得て、10ms毎に認識結果を出力するリアルタイム計算機を考えた場合、10ms でできる計算量には上限があります。
例えば 500MHz で 2000個の DSP のある FPGA だと 「10ms で10G MAC(Multiply-accumulate:積和演算) しか計算できないので、それに収まるネットを探してもってこよう」といった話になり、ResNet-18 とか YOLO とかそういうものの中で性能要件の合いそうなのを探して持ってくる話になりがちです。
この手の一般CNNは各フレームに閉じてた計算しかしませんので、出力には 10G MAC分の認識能力しか得られません。計算している間に実世界で対象に起こる予測不能な運動による誤差を減らそうと、フレームレートを上げるほどに貧弱なネットワークモデルしか適用できなくなり認識性能が出なくなっていきます。
一方で、動画に関しては前後のフレームに相関があるので、認識結果もうまく引き継いで活用すれば、10G MAC分以上の認識能力が出せる可能性があります。この「引継ぎ」に関しては一般に計測対象のダイナミクスに対して十分なサンプリングレートまでフレームレートを上げると大幅な簡略化が可能になる場合が多いです。
例えば 1000fps などの領域に持っていくと、フレーム前後の相関が非常に強くなりますので、より強固なRNN的な時間方向の情報活用ができる可能性があり、「冒頭にあげた動き探索のようなことが起こり始める可能性が無いか?」という仮説が出てくるわけです。
「10ms で 10G MAC のネットワークモデルを 1回計算するより、1ms で1G MAC のネットワークモデルを10回計算する方が精度が良くなるケースもあるのではないか?」というのが私の仮説です。
もし、そのようなことが起こりうるのかどうか(起こるケースが存在するかどうか)を明らかにする研究を行う場合「1G MAC の計算10回で、10G MAC のネット1回を超える性能が出せるネットとは何か?」というところが一番の肝になってきますので、1ms で出来る限られた演算量をシステムの中でどう割り当てるかという点が重要になってきます。
それに対する一つのアイデアとして、ミップマップ形状のRNN などを以前下記のようなブログに書いたわけです。
相関の強さにおいて、近い時間で距離の近いピクセル(解像度の高い画像)ほど相関が強く、逆に遠い時間だと遠いピクセル(解像度の低い画像)でしか相関が出ない確率が上がっていくと考えると合理的な気もしています。そこに「一定時間に使える演算量は有限」という条件を加味してリソース割り当てを考えてみたわけです。
とはいえ、通常はプーリングによる縮小とともに増えていくチャンネル数に対して、構造上固定チャンネル数で縮小していくので、効果が限定的になる面などもあろうかとは思います。
データセットについて
データセットについて質問を受けたのですが、私の考えとして、時間経過を伴う認識を扱う場合
- 動画データのような前後フレームの関係に意味を持ったデータセットを用意する
- 差分画像など1枚の中に変化量を入れたデータセットを使う(イベントカメラなども候補?)
- 普通の静止画データセットにノイズや振動などの時間変化を加える
などがあるかなと思っております。
3がもっとも安直でして、私もこの手法を使っていましたし、SNN(Spiking Neural Network)のような時系列前提でのMNIST認識なんかもこれだと思います。ダイナミックなシーンチェンジの把握ではなくて、単に局所的な認識だけにフォーカスすればこれが適用可能で、同じデータから生成したバリエーションをグループ化してバッチ学習すれば扱うことができます。2も3に近いのですが、データの中に変化量を入れるという面白みはあります。
一方で例えば手話を認識させるとか、動きパターンそのものが情報を持つ場合は1が必須になります。
動画を準備して順番通りに入力することが必須ですし、RNN的なものや強化学習的なアプローチで学習させる必要があるかと思います。要するに学習に必要な計算機リソースもリッチなものが必要で、時間も掛かりますし、そもそもうまく学習が進行するように調整するのも大変です。
結局、「何を実証実験したいのか?」によって作ったり探して来たり加工するデータセットは変るわけですが、
- その原理を証明できる最小の動作は何か?
- それを満たせるデータセットの条件は何か?
といったことをしっかり考えて、仮説証明に必要な最低限のデータセットを用意しないと、計算機パワーもどんどん増えていってしまって成果が出ないまま時間だけ過ぎていくわけです(自分自身で耳が痛いw、 でも BinaryBrain はターゲットを絞ることで GT1030 だけで研究開発やりきっちゃいましたしね)。
実現可能性の話
我々のアプローチの強みは、FPGAなどを使いながら、「計算機アーキテクチャとセットでアルゴリズムを考える」というところにあります。
一方で、「PyTorch でFPGA向けに新しいネットワークを発明した」として、それをFPGAなりに自動変換してくれるツールは存在しないので、実際に計算機として実現できるのかは、また別の研究となってきます。
実際、若い学生さんの中には、数式上成り立ってはいるが実際計算機にしようとしたら「論理合成したらセレクタが肥大化して非現実的なサイズの回路にしかならなかった」とか、「メモリ転送が破綻して全く性能が出なかった」とか、「結局GPUの方が早かった」とか悲しい結果になるケースも多々見てきました。
4年生の卒論ならそれでも十分な成果なのですが、修士や博士となるとそうはいかないので、事前にしっかりと見極めることが重要です(なんて偉ぶってる私は、学士しか持ってませんwww)。
おわりに
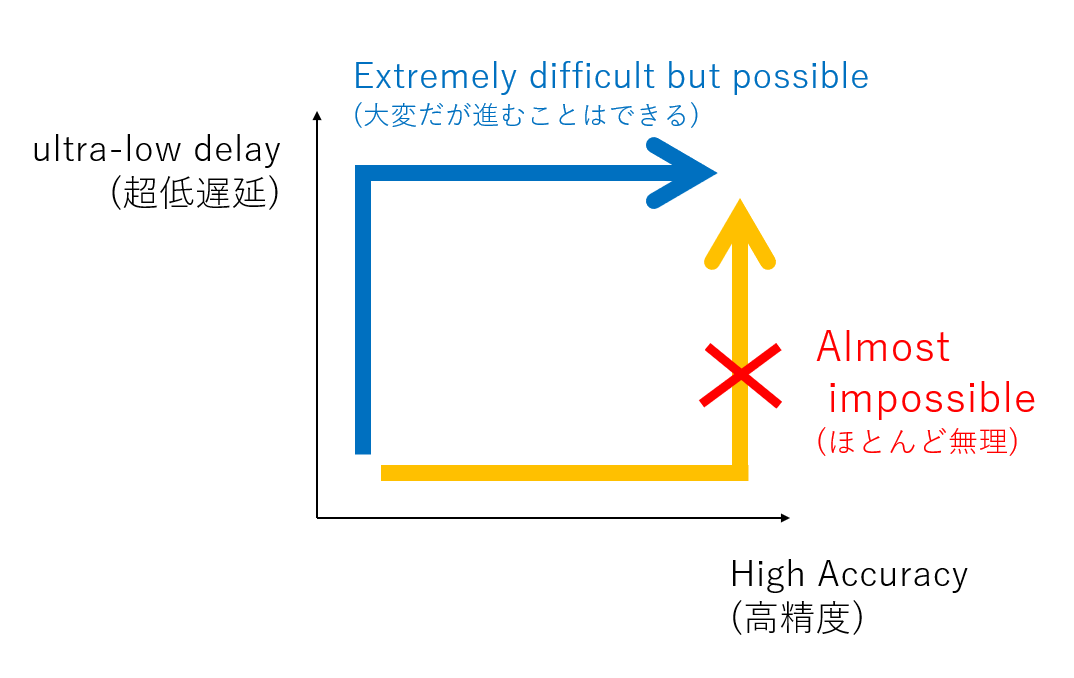
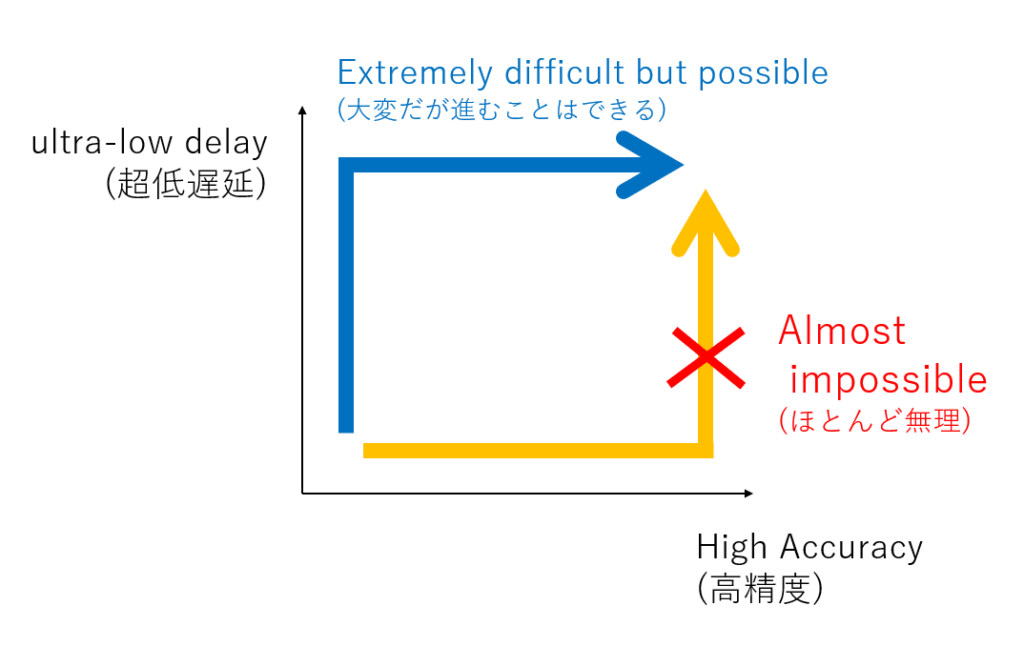
最近、学生さん向けにこんな絵を描いていて、ブログにも張ったりしているのですが、リアルタイムコンピューティングって、「従来コンピューティングを速くしよう」というアプローチだとだいたい失敗するのですよね。
(速くじゃなくて、早くしないとリアルタイムコンピューティングとして価値が出ないという罠がありまして。スループット課題ではなく、計算してる間に世の中方が変化してしまうという課題を追いかけてるわけです。案外この応答速度の問題を計算機の速度の問題だと思っておられる方多くて、「将来計算機がもっと高性能になれば解決する問題です」という方おられるのですが、これ速度じゃなくて構造の問題なので、速くしても早くはならなくて、計算機アーキテクチャを再設計しないといけないのですよね)
「今できていることがなぜできているのか?」をしっかり理解した上で、「どうすればそれを進化させられるか?」という視点で、普通のコンピュータのSOTAな研究を少し違った視点から眺める必要があると思っています。
武器も持たずにレッドオーシャンのAI分野に真っ向から挑んでも容易には成果は出ませんので、計算機科学の分野や、画像信号処理の分野の知見を活かして、まだ誰も研究していない領域を模索するのは一つのアプローチであろうとは思っているわけです。
FPGA上で出来るプログラミングは、CPUやGPUなどの普通のコンピュータ上でのそれに比べるとかなり自由度があるので、難しい反面、ツボを押さえると新しい発見がまだまだたくさんできますので、若い方々の研究に今後も期待したいところです。
コメント