
従来の画像処理の遅延問題
近代のデジタル画像信号処理ではカメラからディスプレイまで大きな遅延が発生します。まずは下記を見てみてください。
加えてAI認識にはGPUなどで行われる大量の演算を行う計算遅延が発生します。
上記の絵のように遅れた画面を見ながら自動車を運転したりしたくないですよね。
人間には一瞬である0.1秒(100ミリ秒)の遅れですら、人が歩く速度(1~2メートル/秒)で、10~20センチメートルも移動してしまいます。カメラのシャッターは一瞬なのに動く物体がブレてしまうのはこのためです。
我々の現実世界では、壁にぶつかってからブレーキを踏んでも手遅れです。
何か作業をするにも、画像認識している間に移動してしまうものが多数あります。画像認識に時間がかかるため、それらを固定して停止させる為の装置や仕組みが沢山あります。
無人レジで、バーコードの前で商品を静止させる行為などは、実は人間がコンピュータの都合に合わせらせられている最たる例です。計算機がリアルタイム化すればもっと低コストで人間に優しい世界に近づけるはずです。
遅延の原因
遅延の原因は様々です。
- カメラが現像処理の為などにフレーム単位でバッファリングして画像処理している
- 計算機の入出力で一度メモリに画像をバッファリングしてから計算している
- GPUは同じ処理の並列計算しか出来ないので、並列数だけ画像データをメモリに溜めてからでないと計算が開始できない
- ディスプレイとカメラが別々のタイミングで動いており(非同期)、待ち合わせの為にメモリにバッファリングが必要
- そもそもHDMIなどの多くのデジタル映像伝送規格が1フレーム時間かけてデータを送る規格になっている
などなどです。
そしてこれらの多くは FPGA を使えば回避できます。
そしてその際に従来の深層学習モデルはそのままでは適用できませんので、低遅延にも応用でき、さらにFPGAリソースを有効に活用できる学習ネットワークとして、LUT-Network が生まれました。
遅延のないAI認識を行うFPGA専用学習モデル
論より証拠という事でまずは下記を見てください。
MNIST(手書き数字)をベースとしたものですが、ほぼ遅延が見えないまるでガラス越しにそのまま見ているような速度(なんと1000分の1秒)で、数字を認識して値ごとに色を付けています。
これはセマンティックセグメンテーションと言い、すべてのピクセルで分類認識を行うという、非常に演算量の多い高度な処理です。
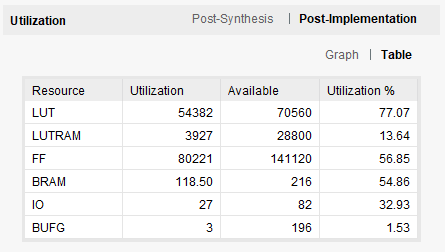
Zynq-7000 (XC7Z020)という安価な部類のFPGAに収まっており、リソース利用状況は下記のとおりです。カメラやディスプレイ制御、メモリ制御などの回路も入っておりますので、実質的にはAI認識部分は半分程度のリソースで収まっていると言えます。
なぜ遅延が起きないのか
これはFPGAを使えば解決する問題ではなく、計算機アーキテクチャとアルゴリズムの見直しが非常に重要です。
- 入力から出力までのデバイスのタイミング同期とデバイスと演算器のバッファレス接続
- 入力された画素から順にパイプレイン演算できるヘテロジニアスな計算機構造
- 前方参照しない各種のアルゴリズム改良
- 前方参照無しで性能を出す為のハイフレームレート化
- これらを可能とするFPGA構造で性能の出るAIモデルの開発
などです。
またこれらを実現するために当サイトではFPGAとカメラを直結する技術として
などの技術を開発しています。
超低遅延認識 LUT-Network(微分可能回路記述の深層学習)
このようなシステムで動作するようなAI画像認識が作れるのでしょうか?
FPGAには乗算器やSRAMなども含まれますが、安価なものだとせいぜい千個程度やそれ以下の数になってきます。これらの演算リソースで1ミリ秒(1000分の1秒)で出来る計算は限られます。
そこで、LUT-Network ではFPGA内に大量に配置されているLUTリソースを活用する深層う学習モデルを発案しました。
詳しくはこちらなどで述べていますが、FPGAで再構成可能な論理回路を記述できるのはLUTのおかげであり、一般的に乗算器の100倍以上の数を備えていることも少なくありません。一方で例えばAMDのFPGAに搭載された6入力LUTであれば64bitのテーブルを備えており、これは一般の深層学習でのINT8が8個分の情報量になります。このLUTは数十万個程度使えば、クロックの1サイクル、例えば500MHz 動作であれば2ナノ秒(1ナノ秒は10億分の1秒)に100万パラメータ分程度の演算ができることになります。
そのために考案した演算モデルが下記であり、LUTを微分可能な近似モデルに置き換えて学習することで、1個のLUTに非常に多くの情報量を持たせることができます。
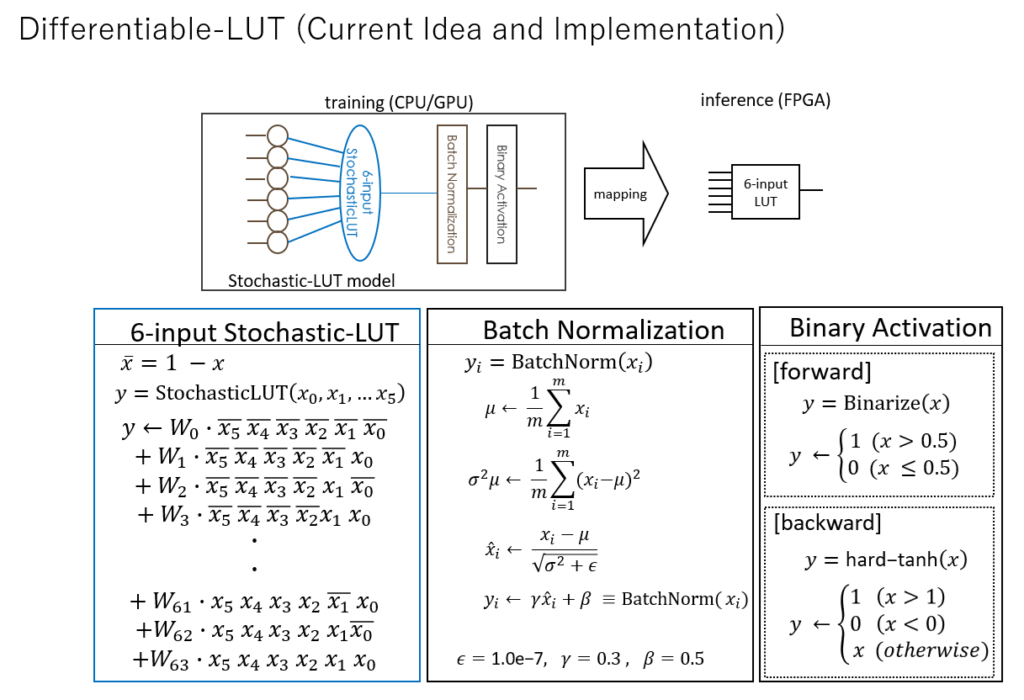
そして、このLUTが何十万個も組み合わさって全体の認識を行うようになります。
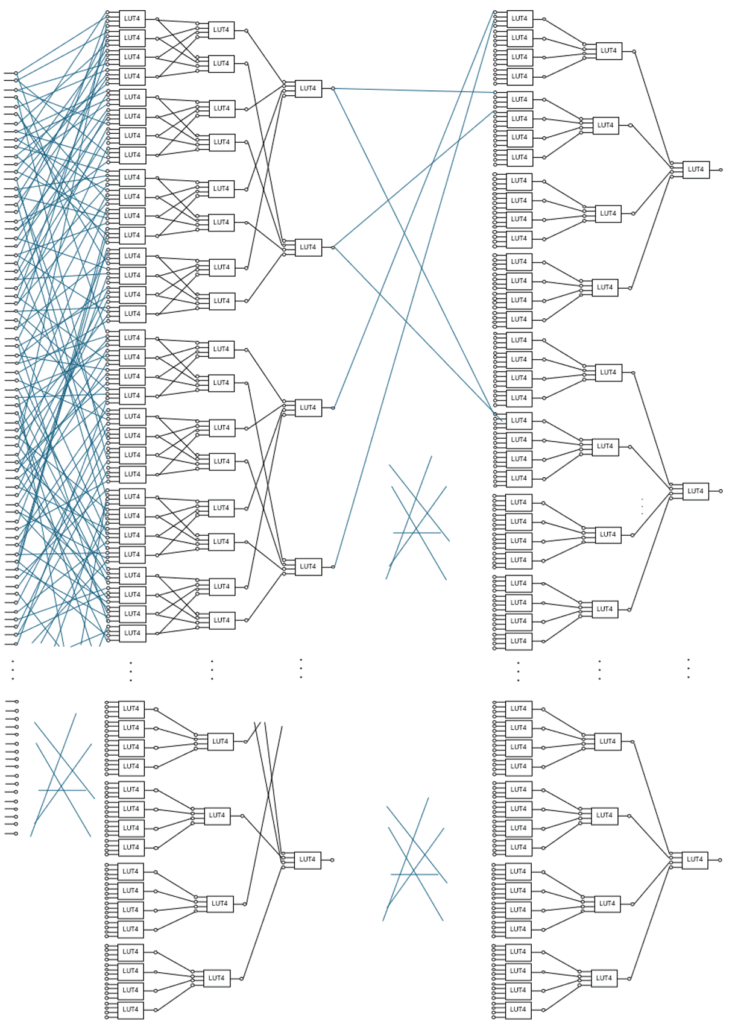
下記はあくまで一例のイメージですが、下記のように何十万個と言うLUTが組み合わさったネットワークを学習することが可能です。これは初めからFPGAの回路構造そのものを学習させているため大変コストパフォーマンス、電力パフォーマンスとも非常に高く、またデバイスのスペック上限に近い周波数で動作可能です。
詳しい情報
各種情報を発信しております。ご参照ください。
- 論文:Fast and Light-weight Binarized Neural Network Implemented in an FPGA using LUT-based Signal Processing and its Time-domain Extension for Multi-bit Processing文
- GitHub:プログラム:独自学習ソフト BinaryBrain
- ブログ記事:LUT-Networkの蒸留とMobileNet風構成とセマンティックセグメンテーション
- Interface 2024年12月号 別冊付録 Tang Primer 25KでFPGA開発 Vol.4 「小さなFPGA Tang Nano4KでAI画像認識」
- Interface 2024年10月号 別冊付録 FPGAマガジン特別版 No.3 Piカメラの高速度撮影とそれを使ったAI処理」