DNN(Deep Neural Network)というといわゆる下記のような構成のものが基本として思い浮かぶかと思います。
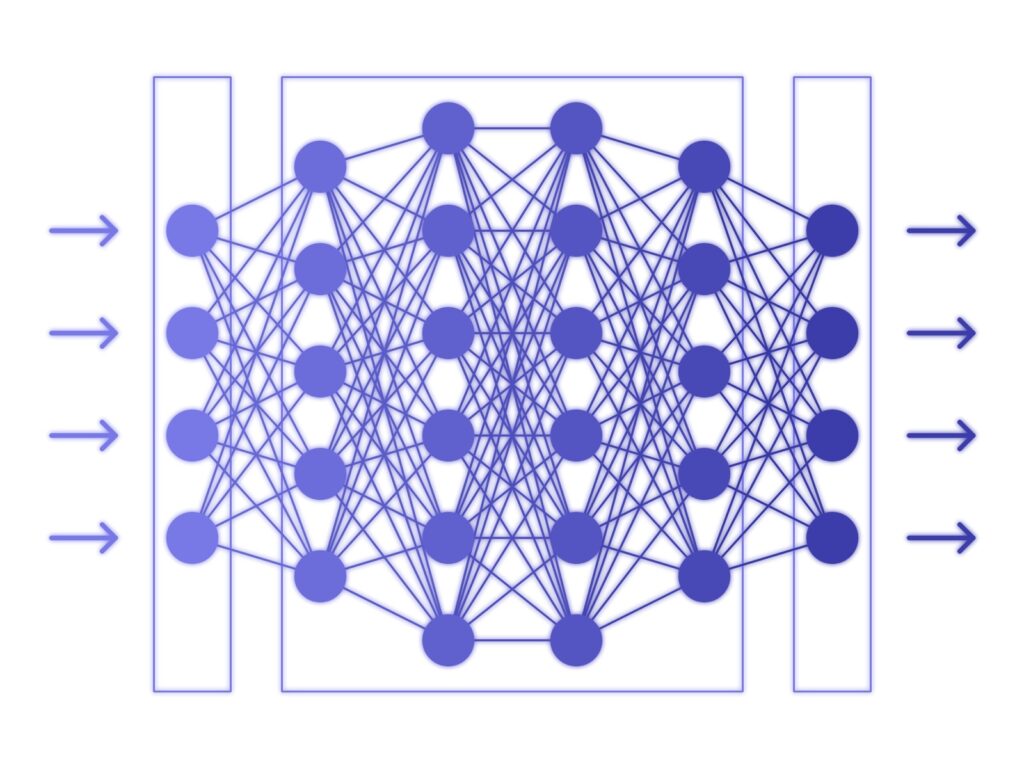
CNN から Transformer までいろんなネットワーク構成がありますが部分を見たときにはネットワーク中にありとあらゆるところに出てくる構成です。
いわゆる全結合層であり、例えば入力と出力がそれぞれ1024チャネルあれば、1024×1024の行列演算となります。
このような場合、積和演算が1024×1024で1M回行われれば計算が完了します。沢山の積和演算器を備えたGPUはもちろんDSPとしてハードウェア積和演算器を多数保有するFPGAにも得意な領域です。
実際に人間のニューロンなどは、1つのニューロンに1万個ものシナプスがあり、他のニューロンに接続されているそうなので、上のモデルよりももっと複雑な接続があるようです。
一方で、BNN(Binary Neural Network)を考えるとき、この構造が非効率化を引き起こしているようにも思えます。
例えばBNNの1つに、パラメータも入出力信号(活性化層)も1bit に量子化してしまう XNOR-Net というものがあります。これは乗算に相当する部分が1bit x 1bit となるので回路としては単なる XNORゲート1個に置き換わることからそういう命名となっているようです。
乗算部分が1ゲートになるというととてもコンパクトに聞こえるかもしれません。しかしながら例えば1024チャネルの入力を扱う場合、最大で10bitになる加算を1023回行って popcountとも呼ばれる総和を計算する reduction 演算が必要になり、最後にやっと閾値と比較して1bitに縮退します。
従来までは積和と言えばニューロンの肝である重みパラメータを乗算する部分のコストが大半だったところ、量子化を進めてネットをコンパクトにすると、大半が加算で電力を消費するという事になってしまいます。
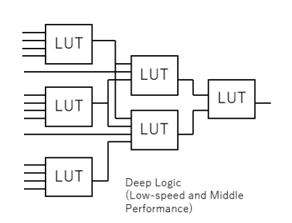
またループを回って計算する場合はもちろん、並列に計算する回路に展開することを考えると、この1024チャネルの入力や、出力が1024個の別のニューロンに繋がるなどのモデルは、デジタル回路においてはfan-in と fan-out に他なりません。タンパク質で立体構造に作られている生物の脳と比べて、シリコン半導体で作られている電気回路にとって、この fan-in と fan-out はフラットに展開すると高コストです。ASICはもちろんFPGAで構成する場合もLUTを多段に構成する必要があり、直接的な演算ではないリソースを消費してしまいます。
とはいえシリコン半導体でDNNを行う上で、必ずしも生物の真似をする必要はなく、半導体にマッチしたネットワークモデルを考えるのは合理的に思います。半導体ゲートに適した fan-in/fan-out で結合されたネットワークモデルを作ればいいわけです。
その点で当方のBinaryBrainは reduction 演算はもちろん BatchNormalization や Binarize などのすべての処理を含めて LUT 1個に収めたうえで、6入力などのFPGAの fan-in に合わせた接続しか用いずにネットワークをモデル化しています(余談ですが 2入力LUTモデルを使うとASICのゲートを直接学習させることにもなります)。
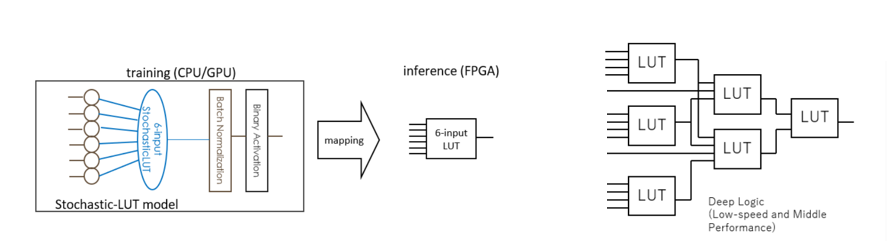
引き換えに、事前にGPGPU等で行う学習がとても非効率で時間がかかるという事にはなっていますが、巨大な乗算の得意なGPGPUで疎結合ネットを学習させているので仕方ない部分かと思っています。
GPGPUなど昨今のAIアクセラレータは生物の脳をモデルにしたネットを高速に実行できるように、頑張ってハードウェアアーキテクチャをそちらに寄せようと努力しています。
一方で、BinaryBrain のように、シリコン半導体に親和性の良いモデルを考えるというのも一つのアプローチなのではないかとは思う次第です。

コメント