はじめに
私が BinaryBrain を開発してからかなり経ってしまいましたが、当時適当に棚上げにしたままにしている技術課題は多数ありまして、原理的なところでまだまだ研究余地は沢山残っています。
下記などでも少し書きましたが、純粋にネットワークの研究としても置き去りになっている部分がまだまだあります。
BinaryBrain を応用した研究についての話はよくしますが、BinaryBrain そのもの研究の話はあまり書いてこなかったので、折角なので数年ぶりに掘り起こして少し記録しておきたいと思います。
ネットワークモデルの研究余地
モデルそのものの改善
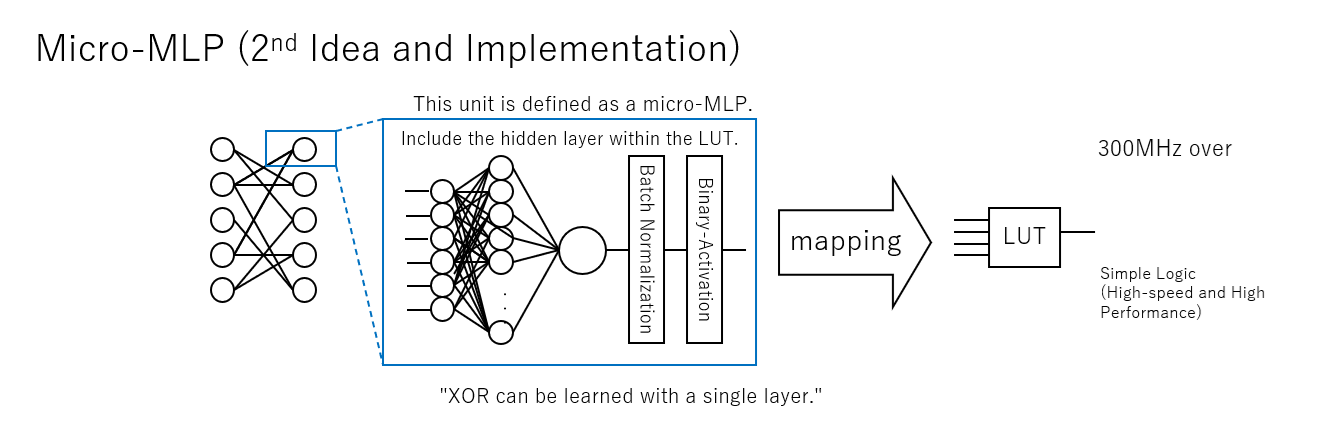
BinaryBrain で LUTを学習させるモデルとして、当初 Micro-MLP と呼んでいた隠れ層を含む多層パーセプトロンを1つのLUTに対応させる学習方法を取っていました。
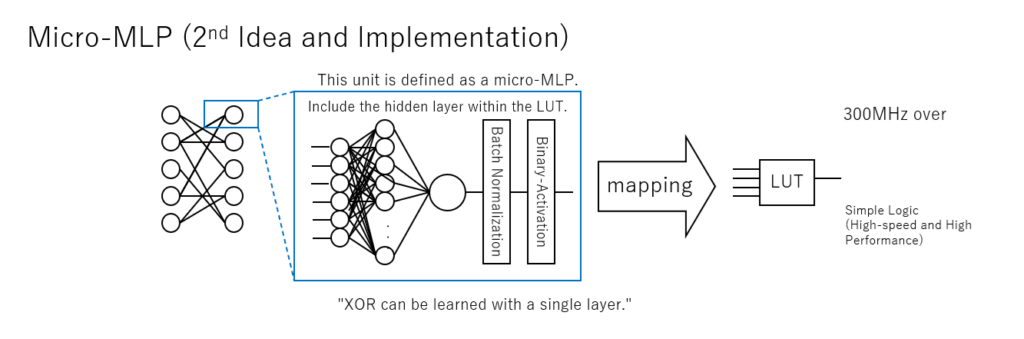
見ての通りの構造ですので、それなりに1個のLUTを学習させるのに計算時間もメモリもそこそこかかっていました。
そこで、もうちょっと何とかならないかなと言うので、微分可能LUTのモデルを発案いたしました。
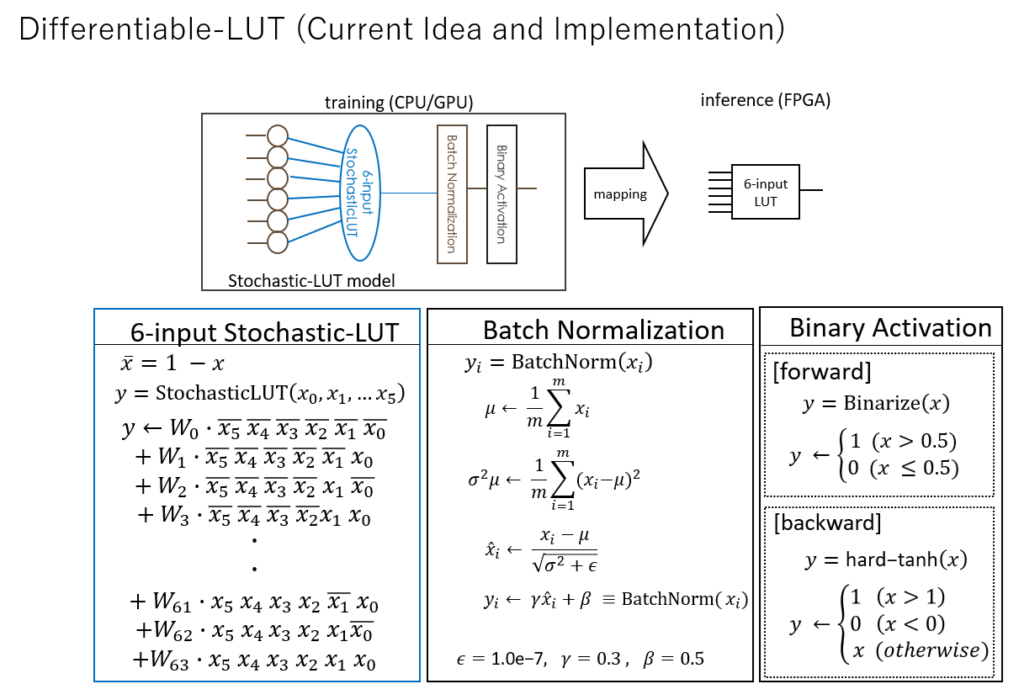
微分可能LUTはLUTテーブルをあるていど直接的に学習させますので、計算効率は良くなりました。しかしながら、そもそもMicro-MLP と比べて精度が良いものができるのかどうかなど、十分な検証ができてないのが実情です。γ = 0.3 、β = 0.5 というのもあれこれ調整して、たまたまその時このぐらいにしたらそれなりに学習が進んだというだけのもので最適値かどうかすらわかっていません。
BatchNormalization もっと別の正規化が使えるかもしれませんし、活性化層ももっと別のモデルがあるかもしれません。
要するにこの基本モデル自体まだまだ発展の余地があります。要はLUTを学習できさえすればよいのでもっと別のモデルもあるかもしれません。
また今は Schotastic な演算をメインに 1 と 0 にしていますが、+1 と -1 表現にするという手もあるかもしれません。
他にも模索できていないものとして自己参照モデルもあります。
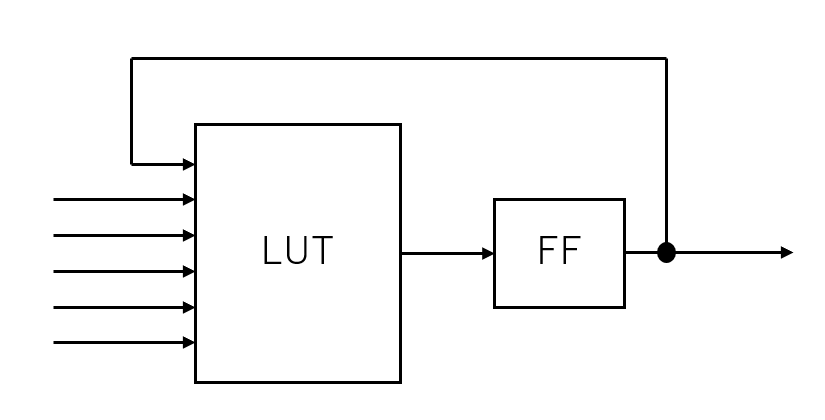
そのままだとRNN的ではありますが、スパイキングネットワークなどのように一度発火したら必ず次のサイクルはゼロになるようにして、パルスしか出せないようにしてテンポラルコーディングのような学習を施す手もあるかもしれません。
結線方法の改善
これもほとんど模索しておらず、今のところ配線混雑しない程度に、シリアル結線とランダム結線を組み合わせているだけです。もっと良いつなぎ方がありそうに思います。
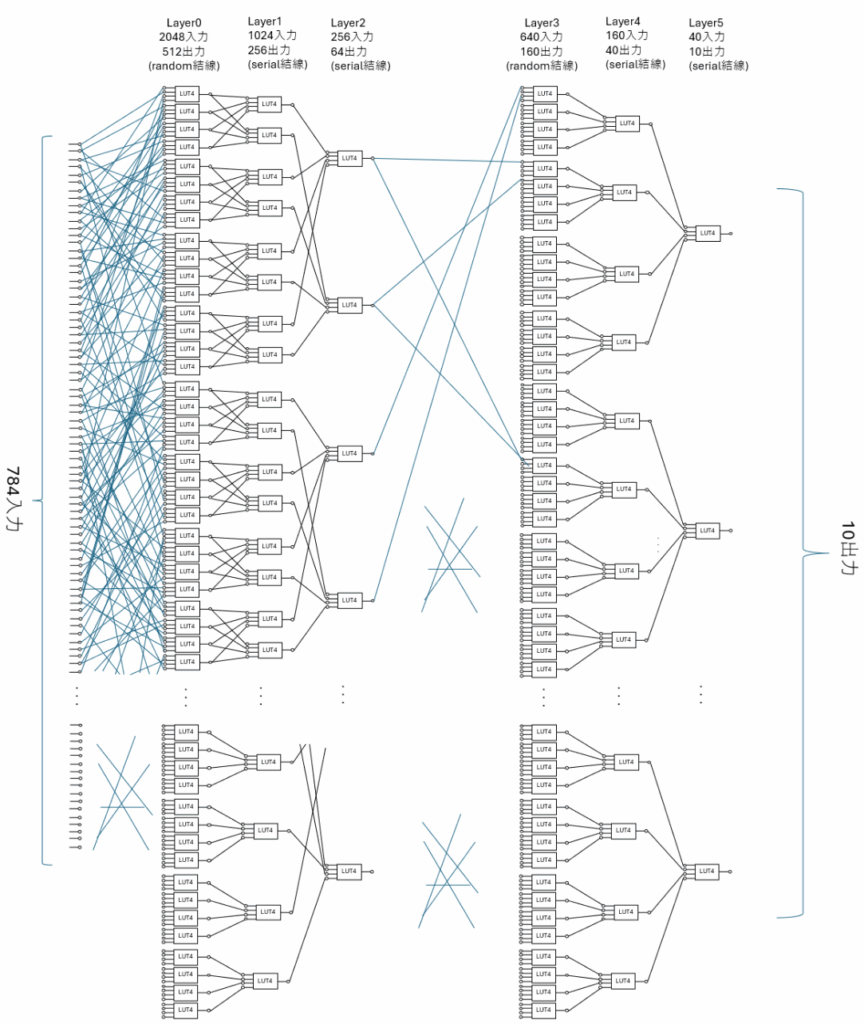
また学習しているとほとんど意味をなさない接続が出てくることもあり、学習中に動的に繋ぎ変えていくようなこともできるかもしれません。
また、他のネットから蒸留する場合は元のネットをうまく参考にして配線を作る手もあるかもしれません。
そもそも微分できさえすればよいのですから、綺麗にレイヤーを作る必要もなく、もっと複雑な構造もありそうな気がしています。
オプティマイザや損失関数など
普通に従来の損失関数や AdaGrad など使っていますが、もっと良いやり方はありそうな気がします。
FPGA以外への応用
今のところFPGAを前提にLUTを想定していますが、2入力LUT などを持ち込むと、これはもうかなりASIC回路を学習させるような世界になります。
またFPGAでは6入力LUTぐらいになってしまいますが、もっと大きなテーブルもあるかもしれません。
そもそも、デジタル値ではなくアナログ値をテーブル引きするような構成も今の学習モデルで扱う事ができるので、全く新しい半導体構造を考えることもあり得るかもしれません。
モデルの分析
例えば Grad-CAM のような分析とか、Explainable で使われているような手法は何も試したことがありません。
LUTテーブルの値の情報密度だとか、学習過程の変化の仕方だとか、LUT-Network 固有の面白い特性がひょっとするとあるかもしれませんがまだ何も解析出来ていません。
他のモデルとの連携
FPGAだけを考えても LUT-Network だけで実用的なネットワークを作るのはやや無理があると思っています。
蒸留に関する研究
LUTネットワークそのもの学習は深いネットワークはかなり難しいので、他のネットワークから蒸留するようなテクニックはかなり重要だと思います。
組み合わせ学習
従来の各種ネットワークと LUT-Network を組み合わせた状態で学習させる手法についてもまだまだ不十分に感じています。
BinaryBrain の学習プラットフォームについて
こちらはややソフトウェア工学的な話になるかもしれませんが、環境も課題だらけです。
- 自動微分の機能がない
- numpy を経由しないと PyTorch などとデータ交換できない
- ONNX のような標準的なデータ交換ができない
- CUDAコードなどもまだまだ最適化できていない
- そもそも全体的に作りが雑
- 新しい Python でインストーラが動かない(苦笑)
など、かなりダメダメな状態ですので、本来であれば一度綺麗に作り直すぐらいの勢いが必要です。
この辺りは研究テーマとしては弱いですが、環境が無いと研究できませんので、何かしら新しい要素を取り入れて新規性を出しつつ再構成できればと思う次第です。
計算機効率の話
あとは当方は、計算機の視点からアルゴリズムの改善を行うのが基本スタンスで、LUT-Net などはまさにそこから生まれた産物なわけですが、その観点でもまだまだ課題は多いです。
- LUT は高密度に利用できたがDSPやBRAMなど他のリソースが遊んでいる(要するに一般的なDNNとのハイブリッド化)。INT8ぐらいの畳み込み層とのハイブリッドはありそう。
- Strideが1より大きいフィルタ(MaxPoolingなども含む)を使うと、後段の演算器が遊んでしまう問題。後段にピクセル単位の再利用型の演算器構成を作るとか、ミップマップ構造のフレーム単位再利用構成を作るとかで演算器利用効率の高い構造を考えないと計算機効率が上がらない。
- シフトレジスタを使ったLUTとか、RAMを使ったLUTとか再構成可能な LUT-Net の構造研究もまだあり得そう。
などなど、いろいろ気にはなっております。
おわりに
ざっくり、思いつくがままに少し書いてみましたが、やりのこしたことばかりだなと思う次第です。
なかなか自分でもじっくり腰を据えて取り組むタイミングがなさそうですので、研究したいという学生さんとかおられましたら是非に。
![ゼロから作るDeep Learning Pythonで学ぶディープラーニングの理論と実装 [ 斎藤 康毅 ]](https://thumbnail.image.rakuten.co.jp/@0_mall/book/cabinet/7584/9784873117584.jpg?_ex=128x128)

コメント