ここ数年、若い学生さんとかやり取りする機会を頂いておりますが、特にAI方面の興味からFPGAに挑戦しようとする方々で、カメラとか計算機アーキテクチャとかハードウェア方面から少し遠い方々に、いろいろと私がやっていることが正しく伝わってなかったり、誤解を与えているケースがあります。その際、少し共通項が見えてきた気がするので少しフォローする記事を書いてみたいと思います。
HLS(高位合成言語)でもいいのですが、RTL(SystemVerilogなど)だとより鮮明に根本的な課題が見えてくるので少し具体的な例を書きますと、「我々のやっているFPGAを使ったリアルタイムビジョン用に画像認識をするアルゴリズムを検討してみてください」というお題に対して、例えば MNIST(28×28 の 8bitグレースケール画像の認識)などを手を付けようとすると、頭の中に下記のようなモジュールを作ることを思い浮かべてしまうようです(まあ普通はそう考えちゃうよね、とは思いますが)。
module mnist_recognition(
input var logic reset , // リセット
input var logic clk , // クロック
input var logic [27:0][27:0][7:0] in_image , // 入力画像
output var logic [9:0][7:0] out_class // 各クラスのlogits出力
); しかしながら我々は低遅延でリアルタイム性の高い認識アルゴリズムを計算機アーキテクチャとセットで考えようという取り組みをしております。
残念ながら 28x28x8bit でいきなりデータを出してくれるようなカメラは一般には存在せず(無いわけじゃないですが)、産業応用などを考えると下記のようないわゆる左上から右下に走査しながらデータの出てくるカメラを想定することになります。
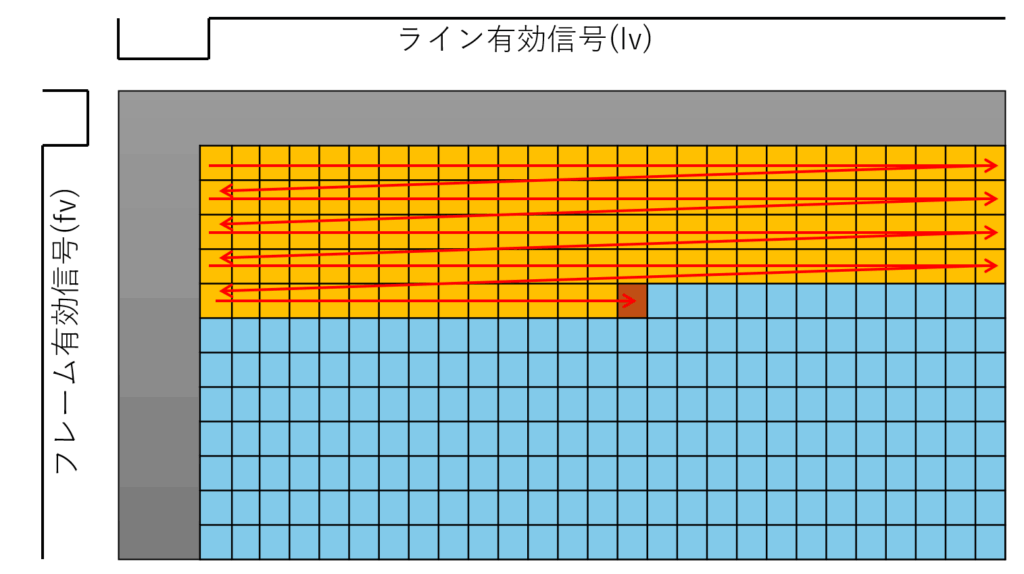
したがって例えば下記のようなイメージを最初に持つことが重要です。
module mnist_recognition(
input var logic reset , // リセット
input var logic clk , // クロック
input var logic in_fv , // フレーム有効信号
input var logic in_lv , // ライン有効信号
input var logic [7:0] in_picxl , // ピクセル値
output var logic [9:0][7:0] out_class , // 各クラスのlogits出力
output var logic out_valid // 出力有効信号
); 要するにピクセルクロックで毎サイクル1ピクセルずつデータが入ってきて、これに対して何とか演算器を稼働させ、結果が確定した段階で出力するというイメージになります。
困ったことにHLSで書くとこの両者のどちらを実装する場合も同じようなインターフェース宣言で始められてしまうものだから、過去には「修論提出直前までインターフェースが合わないことが発覚しなかった」なんて例もあったりします(研究成果が、リアルタイム認識じゃなくて、ただの画像認識のFPGA実装になっちゃった)。
ここで、具体的にリアルタイムビジョンとは何なのかと言うのを、以前こちらでブログ記事に書いたセマンティックセグメンテーションのアイデアの例を使って少し説明しようと思います。
マンティックセグメンテーションだと入力ピクセル数と同じ数だけ分類結果が出てきますので、下記のようなポート定義になります(実際は AXI-Stream とかにしますが、まあ例なので)。
module semantic_segmentation(
input var logic reset , // リセット
input var logic clk , // クロック
input var logic in_fv , // フレーム有効信号入力
input var logic in_lv , // ライン有効信号入力
input var logic [7:0] in_picxl , // ピクセル値入力
output var logic in_fv , // フレーム有効信号出力
output var logic in_lv , // ライン有効信号出力
output var logic [9:0][7:0] out_class , // 各クラスのlogits出力
);
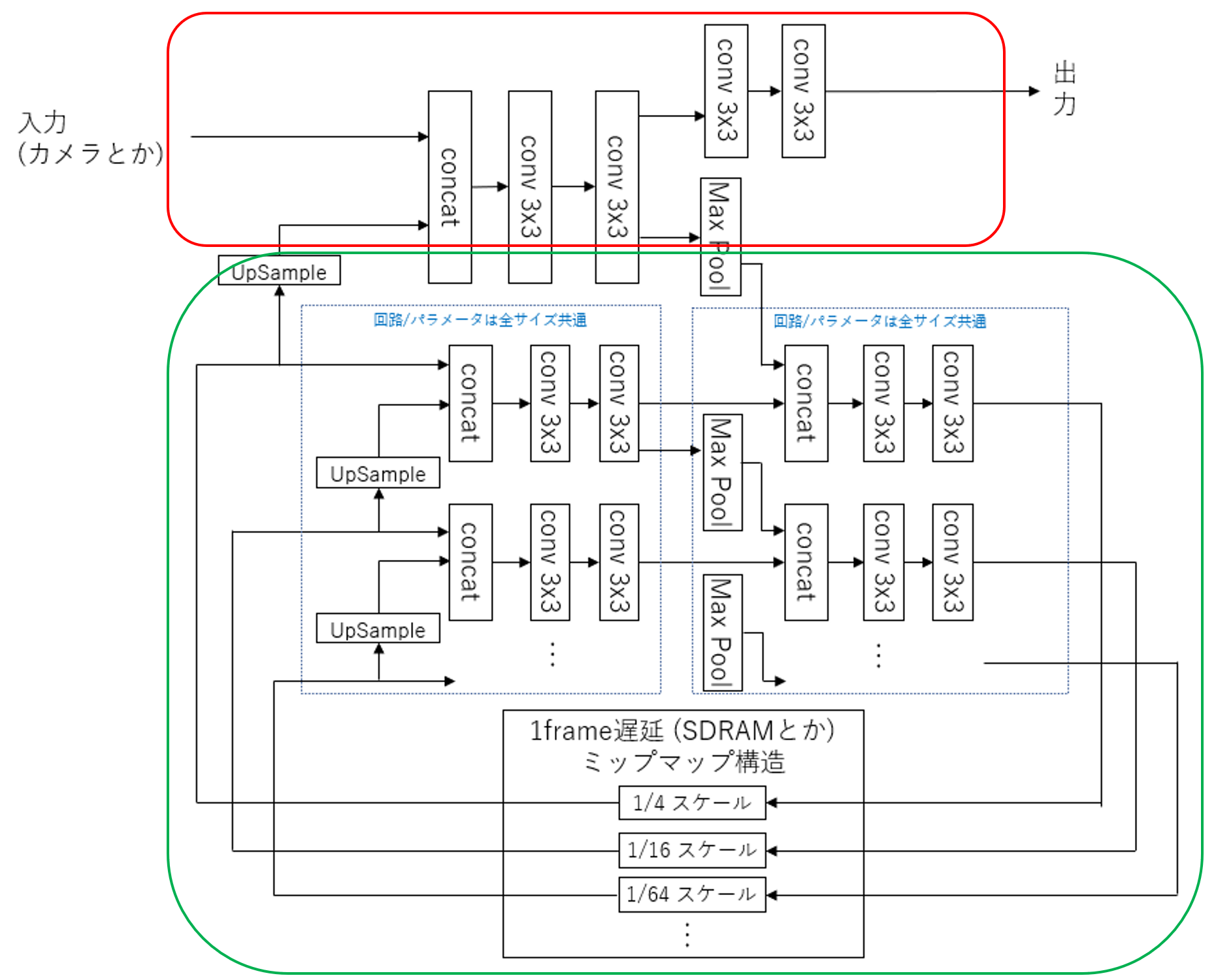
下記のアイデアは PyTorch ではまあ少し動いていたので理屈上は動くだろうとは思うのですが、ともかく赤枠の部分と、緑枠の部分に大きく分けられます。
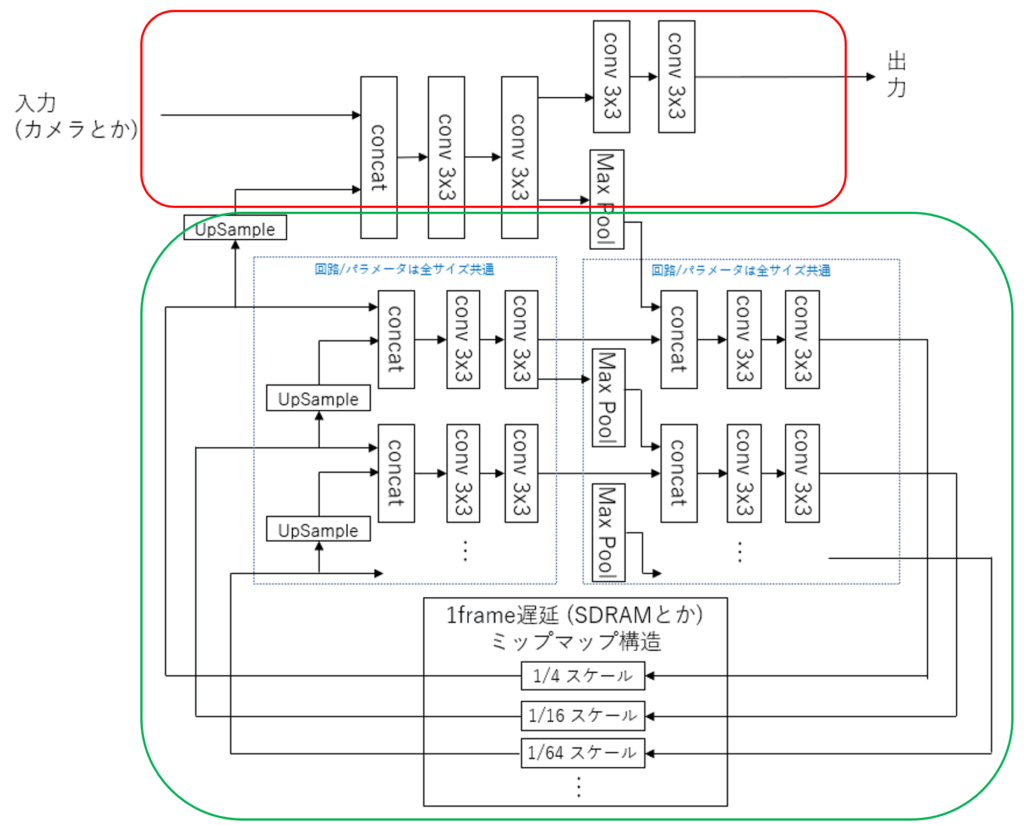
私が公開しているLUT-Networkでのセマンティックセグメンテーションなんかは赤枠の部分だけを増強して構成しているわけですが、まずこの部分がリアルタイムビジョンの肝になります。
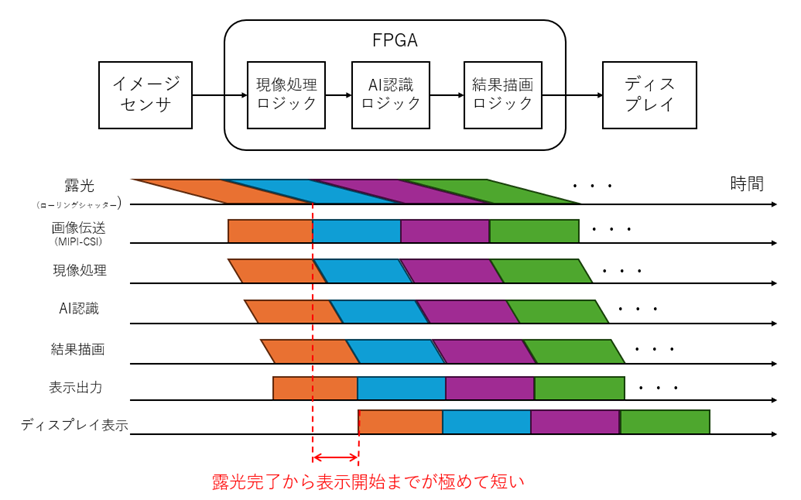
ここでは例えば入力から出力までの最短経路の中で3×3の畳み込み(Convolution)層が4つあるわけですが、3×3の畳み込みはまず2ラインをバッファリングしないと計算対象が揃いませんので、ラインバッファでバッファリングするわけですが、4段でトータルで8ライン時間の遅延となります。そしてスループットとしては1/1であり、毎サイクル新しく1ピクセル入力され、毎サイクル新しく1ピクセル分の分類結果を出力します。
ここがリアルタイムビジョンの肝で、FullHDだろうと4k画像だろうと、常に8ライン時間しか遅延が無いのです。これは画像全体の1フレーム時間から見ると十分小さく、極めて低遅延で応答性の高いリアルタイム認識です。画素単位で見たときは、あるピクセルが入力されたとき数ライン時間(マイクロ秒オーダー)でそのピクセルがどのクラスに属するか出力してるわけです。
一応露光時間なども含めてミリ秒認識を謡っていますが、実際はマイクロ秒オーダーと格闘しながらアルゴリズムと回路の設計をしていまして、そこまでやって、且つ、動くシステムまで組み上げて初めてリアルタイムビジョンを名乗っているわけです。
一方で、将来性を考えたとき、この赤枠の部分だけのやり方では、例えば 28×28 の MNIST 画像を認識したければ、 27ライン遅延が必要になりますし、大きなものが認識できないという課題があります(傷検知とか小さなものには十分有効ですが)。
そこで、緑枠部分の登場です。我々は1000fpsなどの高速度撮影を行うことで、従来なら1フレームの間に何十ピクセルも移動してしまう物体も、数ピクセル程度の移動範囲に収まるぐらい高レートでサンプリングすることを信条としていますので、大きな物体の概観を掴むのは前のフレームの情報でも困らないというのがあります。U-Net などが一度 Pooling 層で縮小して全体を把握して、再度アップサンプリングしてセマンティックセグメンテーションを行いますが、リアルタイムコンピューティング観点で、最新の情報が必要な部位に着目すると、それは高解像度部分だけであり、それ以外は過去の情報から得ても良いわけです。実際対象物がフレームインしてきてから数フレーム後から追跡できたとして、1000fpsの数フレームは数ミリ秒ですからさして困らないことになります。
ただ当然これを実現するには赤枠部分のアーキテクチャを壊さないように実現しないと意味がないですのでそれなりに大変です。
この話ははるか昔からこの辺りでも言ってるアイデアではあるのですが、なかなか実装に移せていない理由がいくつかあります。
- フレーム単位の大きなRNN構造になるので PyTorch でも学習が大変、LUT-Net でやるには私の手元の安いGPU じゃ無理そう。
- カメラのタイミングを合わせてデータを持ってこれるミップマップ構造用のDMAの開発が必要(それなりに体力がいる)
あたりでしょうか。
もっともDMAとかの実装の話だけなら今ならHLS(高位合成言語)などをうまく使えば省力化は可能なのですが、例によって LUT-Net の実装がHLSと相性が悪かったり、ちゃんと狙ったアーキテクチャを出力させられるだけのHLSマスターになるのは大変とかまた別の問題がいろいろあったりもします。
いずれにせよ、開発規模面で、ある程度計算機設計の大変さを織り込んで研究計画を立てないとなかなか取り組みずらい部分はあります。
とはいえ、学習モデルも計算機の構成もどちらもFPGAで作るとしたら新規性のあるものですので、フェーズを分けて、部分的な検証から始めていっても良いのではないかなとは思う次第です。

余談で、少しHLSの話をすると、HLSはなまじC++でアルゴリズム自体はプログラム自体は書けてしまうので、学生さんが誤ったハードウェアを頭にイメージしていても指導側が容易に気づけないなんてことが比較的多いです。隣に座って指導できるならともかく、ある程度自主性に任せて進めてもらうケースだと、本人自身がうまくいってると思い込んでしまう率が高い気がします。これはソフトウェアがコンパイルエラーさえ出なければとりあえずOKなケースが多い為、FPGA開発も同じようなものだと思ってしまう部分があるように思います。
ちなみにリアルタイム性のないものをHLSなどで書いてただ合成するだけならGPUで実行したほうがマシとなってしまいますので、折角FPGAを使うからにはやはりきちんと計算機アーキテクチャを設計してから実装に入る必要があります。
アーキテクチャを考えないままとりあえず何か書き始めるという学生さんは、まあどこにでも必ずいますし、私の若いころも似たようなものなので他人のことは言えないのですが、HLSは特にこの傾向を助長しているような気がします。
こういうこと考えていると、とりあえず一度はRTLで書く経験はしておいた方が良い気はしています。


コメント