はじめに
以前、AXIバス や AXI Stream などで使われている valid/ready 方式のハンドシェークについて、下記のようなブログを書きました。
一方で相変わらず、Verilog 初学者が嵌りやすいポイントであると思っています。
RTL記述が適している一直線に処理できるパイプライン処理は比較的わかりやすいのですが、ready 信号と言うバックプレッシャーの仕組みが入ったとたんに難易度が上がります。そしてなまじシンプルなので理解はできるのですが、なぜか実装するとバグるというのを私自身経験しましたし(というか今でもバグ書きますし)、ここ20年ぐらいFPGAを薦めた非常に多くの皆様を苦しめている気がしています。
とはいえCPUの命令実行のストールなどもっと面倒なバックプレッシャー処理は山ほどありますので、最初の一歩としてとても重要になります。
そこで、改めてもう少し深堀しながら、今度は回路図を書くのではなく、ソフトウェア的フローとしてコードを眺めながら何が難しいのか見ていこうと思います。

valid/ready 制御を深く見てみる
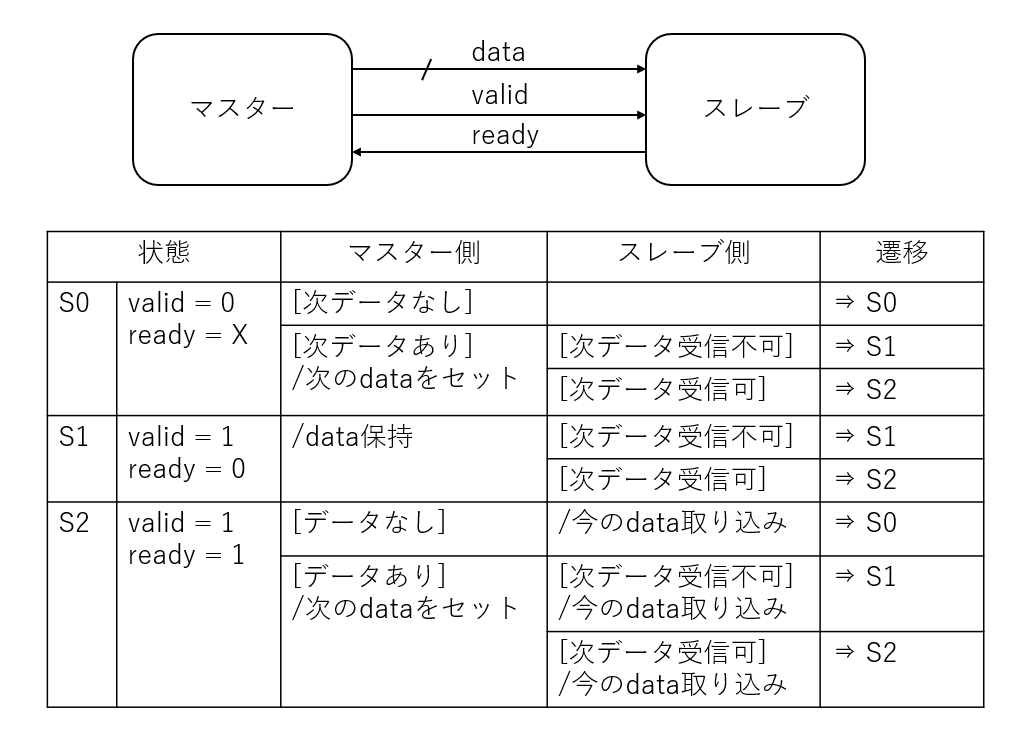
状態遷移表を書いてみる
何らかのマスターデバイスとスレーブモジュールがあり valid/ready のハンドシェークでマスターからスレーブへ次々とデータを渡していくことを考えます。
その際のルールは下記のようなものです。
- マスター側は送りたいデータがあるときは データとともに valid を 1 にする
- スレーブ側はデータが受付可能なときに ready を 1 にする
- マスター側が valid を 1 にするか否かの判断に ready を使ってはならない
- クロックエッジが来た段階で valid と ready の両方が 1 であればデータ転送成立とする
- マスター側は valid を 1 にした後は、データ転送が成立するまで valid も data も変化させてはいけない
などです。
で、このルールで状態遷移表を書いてみようとしたら案外悩みました。
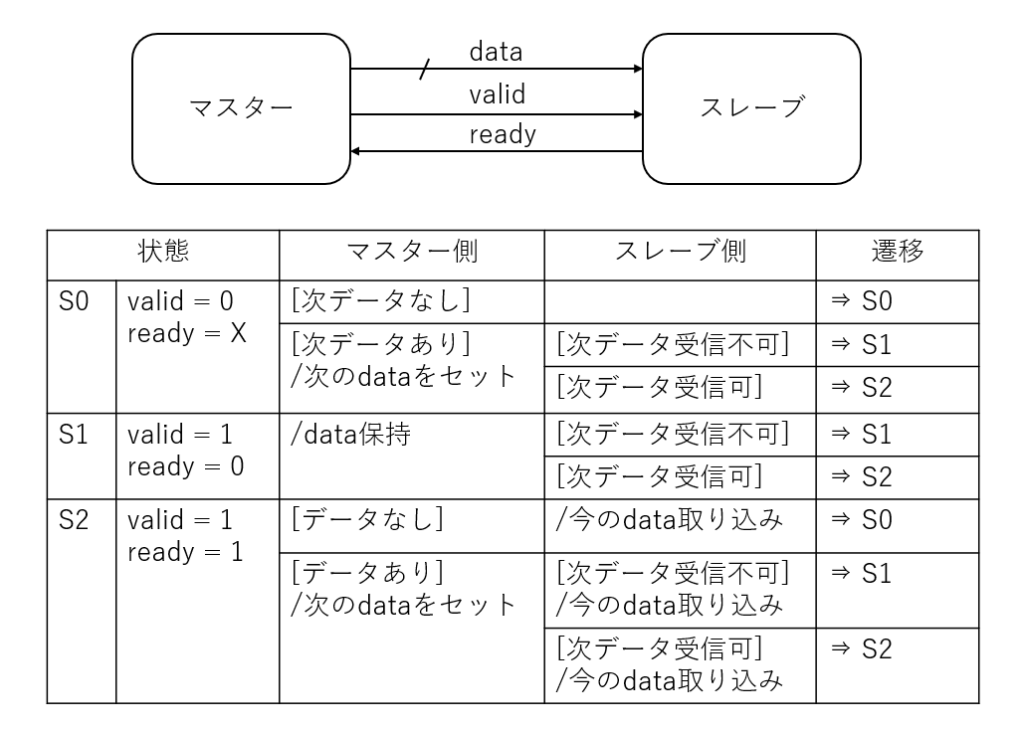
理由としては、マスターとスレーブはそれぞれ独立して設計するにもかかわらず、両方の状態を加味しないとインターフェース部分の valid と ready の次の状態が決まらない というところにある気がします。
これでは、マスター側を設計するときにどうすればいいのか、スレーブ側を設計するときにどうすればいいのか、独立した設計に落とし込むのが難しい気がします。
また、バスアービタのように複数の接続を調停する場合など、遷移表はなかなか複雑になりそうな気もします。

具体的なサンプルを書いてみる
少々無理のある想定だよなと思いつつも下記のような2つの例を書いてみました。
マスター側は「データがあれば送信を要求」し、受信側は「busyでない、もしくは、データが2なら受け付ける」と言うものです。
module master(
input var logic clk ,
output var logic [7:0] data ,
output var logic valid ,
input var logic ready
);
always_ff @(posedge clk) begin
if ( !valid || ready ) begin
if ( 次のデータあり ) begin
data <= 次のデータ;
valid <= 1'b1;
end
else begin
data <= 'x;
valid <= 1'b0;
end
end
end
endmodule
module slave(
input var logic clk ,
input var logic [7:0] data ,
input var logic valid ,
output var logic ready
);
logic busy ; // 受信不能
logic rx_en ; // 受信データ有効
logic [7:0] rx_data ; // 受信したデータ
always_ff @(posedge clk) begin
busy <= 次の状態;
if ( valid && ready ) begin
rx_en <= 1'b1;
rx_data <= data;
end
else begin
rx_en <= 1'b0;
rx_data <= 'x;
end
end
assign ready = !busy || (valid && data == 2);
endmodule動作例としては例えば下記のような感じです。
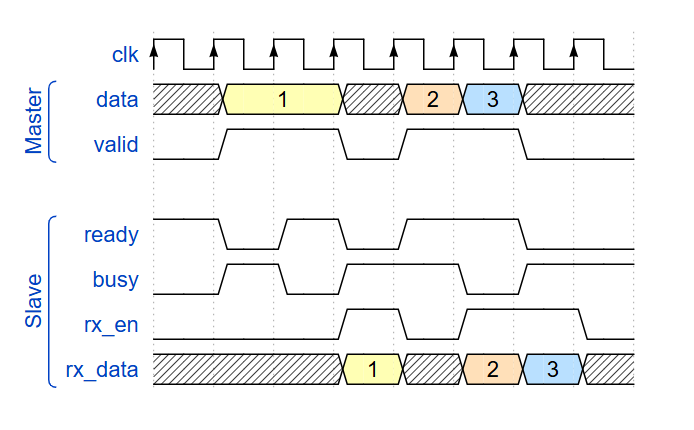
マスター側は input は ready しかないのに、valid を 1 にするのに ready を見てはいけないルールなので、自己都合だけでデータがあれば valid を1にする動作しかできません。
そして、valid を 1 にした後にやってくる次のクロックエッジ時点で ready も 1 なら受け付けられたことになります。つまり valid を 1 にした後にそれが受け付けられたかどうかを知るのはその次のサイクルになります。
次にスレーブ側は自己都合の busy を 1 や 0 にするようにしてますが、ここがややこしいところで、スレーブ側は valid を見て ready を作っても良いルールです。なので assign 文などを使って組み合わせ回路で、「busyでない、もしくは、データが2で ready = 1」というようなコードが書けてしまいます。
実際、波形を見てもらうと data = 2 の個所では、busy = 1 なのに ready = 1 になっています。
フローチャートを書いてみる
ここでおもむろにソフト屋っぽく、マスター側とスレーブ側でそれぞれ分けてフローチャート的なものを書いてみることを試みます。
なお SystemVerilog の場合、ある時刻のタイムスロットの処理で、ACTIVEリージョンで代入予約だけ行って、NBAリージョンで実際に代入されるというような事が起こるわけですが、そのような挙動は理解の上で、ノンブロッキング代入を読んでください。
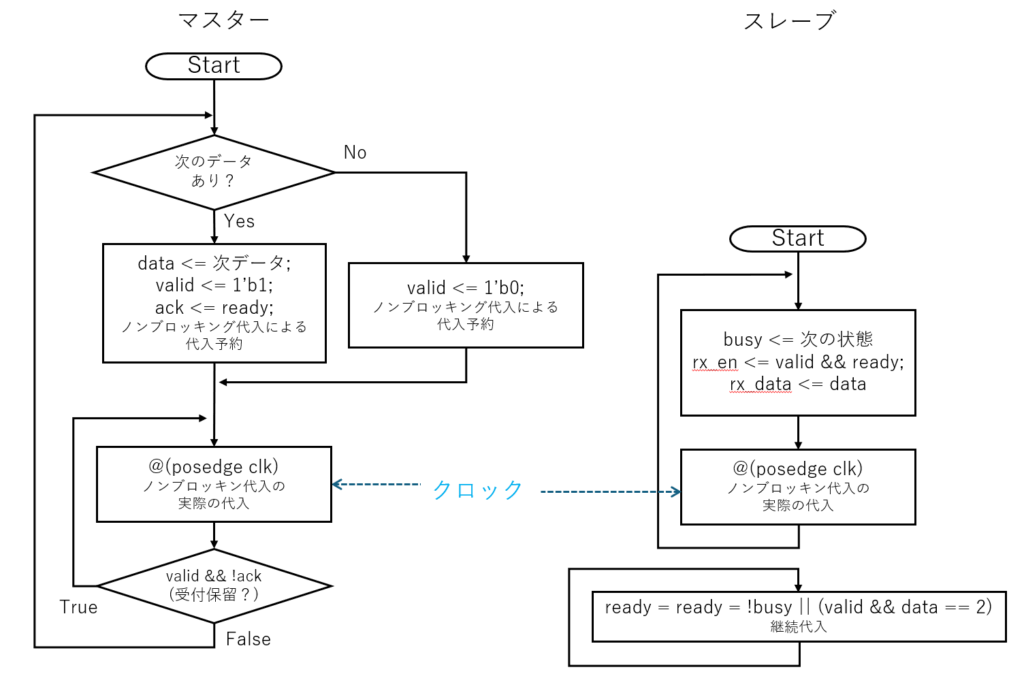
まずマスター側を見てみますが、先ほど valid を 1 にした後にそれが受け付けられたかどうかを知るのはその次のサイクルと書きました。なので @(posedge) でクロックエッジを待ってから受け付けられたかどうか判定して分岐するフローチャートにしています。
もちろん SystemVerilog の文法上、always_ff の先頭でイベント待ちするわけですが、解釈的にはここに持ってきて読み替えた方がわかりやすかったので移動させてみました。
「無限ループなのでどこから書き始めても等価でしょ」という乱暴な書き方をしております。
(ある意味 @(posedge clk) は CUDA の __syncthreads() みたいなものとも言えるかもしれません。)
次にスレーブ側ですが、こちらもデータの受付に関しては、とにかくノンブロッキング代入で取り込んで、「valid と ready の両方が1だったならその時のデータ有効だよ」という後付け判断をしておりこれが一番簡単です。
ただし、スレーブに関しては valid に依存して ready を作っていいことになっていますし、こちらが ready をどう弄ろうが valid に変化が起こらないことが保証されています。なのでクロックエッジを待たずに、次のエッジでは必ずvalidとreadyが1になるようにするという次のクロックエッジを待たずに起こる事象を確定して別の信号を作り始めるような制御も出来てしまいます(今回のSystemVerilogのコードにはいないですが)。
ある意味でスレーブ側の方がマスター側よりわかりやすいのですが、ポリシーが違うため、例えばバスアービタなどの同じモジュールにマスターもスレーブも入っているのを書くときにとても混乱するわけです。
おわりに
定期的に valid/ready は記事にしたい欲求の波がやってくるのですが、今回もまったくもってうまく説明出来た気がしません。うまい表現方法が出来ないという事は私もまだ理解しきれていないのかもしれません。
分かってしまえばなんてことは無いような気もしますが、今の段階でも嘘書いてる部分や間違ってる部分がありそうでドキドキしてますが、とにもかくにも valid/ready の壁に悩んでいる初学者の気づきになる事が1つでも書けていたらいいなと思う次第です。
あとまあ、AXIやAXI-Streamなどが扱えて valid/readyに悩まなくて済む高位合成言語(HLS)が流行る理由の一つでもあるのかもしれないななどとは思いました。

追記的まとめ
Xなどでも少しご意見いただきつつもう少し深く考察してみたところ
- 厳密に言うとFFの値が状態で、イベントはクロック立ち上がりただ一つだが、それだと状態遷移表はただの1列の縦長の表になるだけで状態遷移表の意味合いが薄れる。
- なので、クロック時の入力変化をイベントとみなすが、そうすると、真の意味で同時にいろんなイベントが起こる。これは、mutexやスピンロックなどの排他制御も含めた、イベントを1つずつ処理する(イベントは同時に1つしか起こらないとみなせる)CPUなどでの処理と本質的に異なる。
- さらにクロック時の入力変化のみをイベントとすると、組み合わせ回路で次のクロックを待たずにアクノリッジを返してくる相手に、モジュールに閉じた表が書けなくなる(表にあるイベントと別のところで状態遷移先に分岐条件を作ってしまう)。
などがある気がします。
Verilog の always 文は、CPU での処理だと、タイマ割り込みハンドラに近いものはありますが、真の意味で同時に動いており、時間を待つというよりも、他の always文との同期の意味が強いです。文中、CUDA の __syncthreads() と書きましたが、OpenMP の #pragma omp barrier や、あとはあえて言うなら join() などが近い程度で、他に似た機能があまりCPUの世界にはないような気がします。
この辺りが、CPUのプログラミングから、RTLのプログラミングに入ってくる人の一つの敷居になってる可能性はあるのかもしれません。
まあ、GPUプログラミングを始めるときの別の意味での敷居がありますし、綿らしいプログラミングパラダイムを覚えるの少なからず難しいものが出てくることがあるのだなと思う次第です。


コメント