はじめに
当方はリアルタイムコンピューティングをやることを主軸に計算機アーキテクチャやアルゴリズムを考える事をメインに活動しおります。とりわけFPGAを用いたアプローチは有効で、FPGAを使った Real-Time OS であったり、オプティカルフローのビジュアルフィードバックであったり、カメラの高速駆動など、様々な取り組みをしてきております。
これらはリアルタイム性は置き去りにしてスループットばかり追い求めるGPGPU分野などとは方向性の違うアプローチであり、ニッチな分野ではあれ、レッドオーシャンで戦う体力のない個人開発や小規模研究としては取り組みやすい分野でもあります。
ですので当方の取り組み自体にAIは必須ではないのですが、AIが出来て困ることもないので、リアルタイムコンピューティングの枠組みの中で使えるAIも検討しております。そういった中で LUT-Network というアイデアにたどり着き、BinaryBrain などをリリースさせて頂いたのをきっかけに「FPGAでAIがやりたい」という方々との交流も増えてきております。
FPGAでAIを行う場合のいくつかの種類があると思います
- FPGAを前提としつつも、AIモデルや方式そのものに新規性/進歩性がある
- AIモデルそのものには新規性はないが、計算機アーキテクチャに新規性がある
- AIモデルにも計算機アーキにも進歩性はないが他との組み合わせ応用に新規性がある
などです。
ここで困ったことに、LUT-Network などが、比較的 1. の側面を持っていたために、リアルタイムコンピューティングを置き去りにしたままの議論になる事も多く、結果として何の新規性も生れてこない空中戦の議論に終始してしまう事も増えてしまっているようにも思います。
そこで、再度リアルタイムコンピューティングとAIを整理しておこうと思います。
基本的に画像認識などセンシングにAIを使う話になると思います。
リアルタイムにAIをやる価値
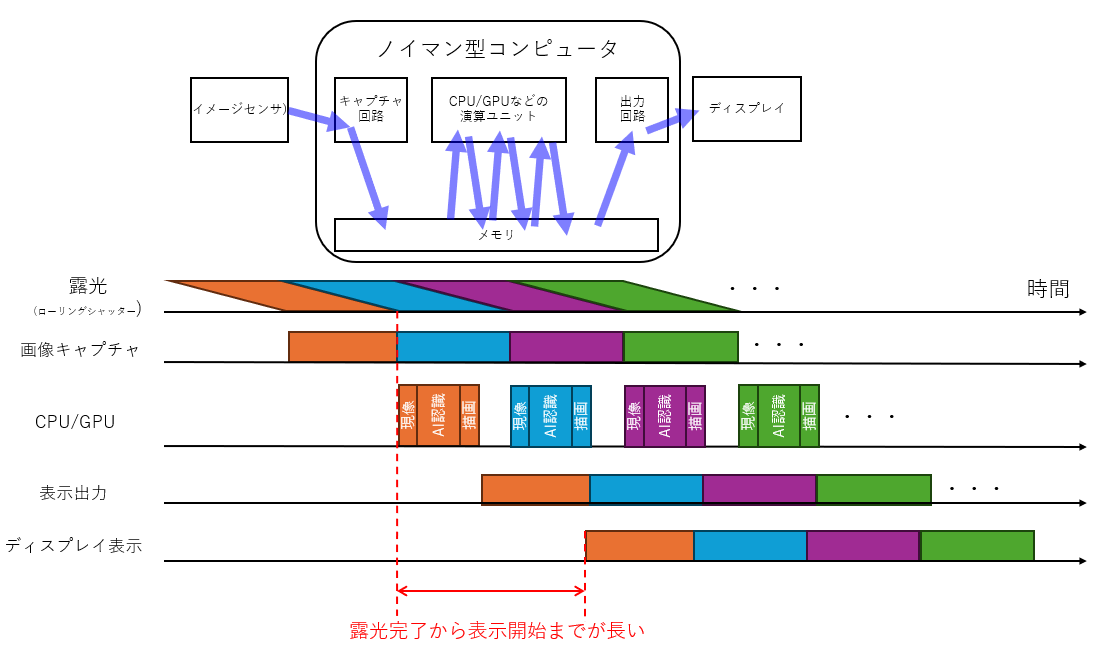
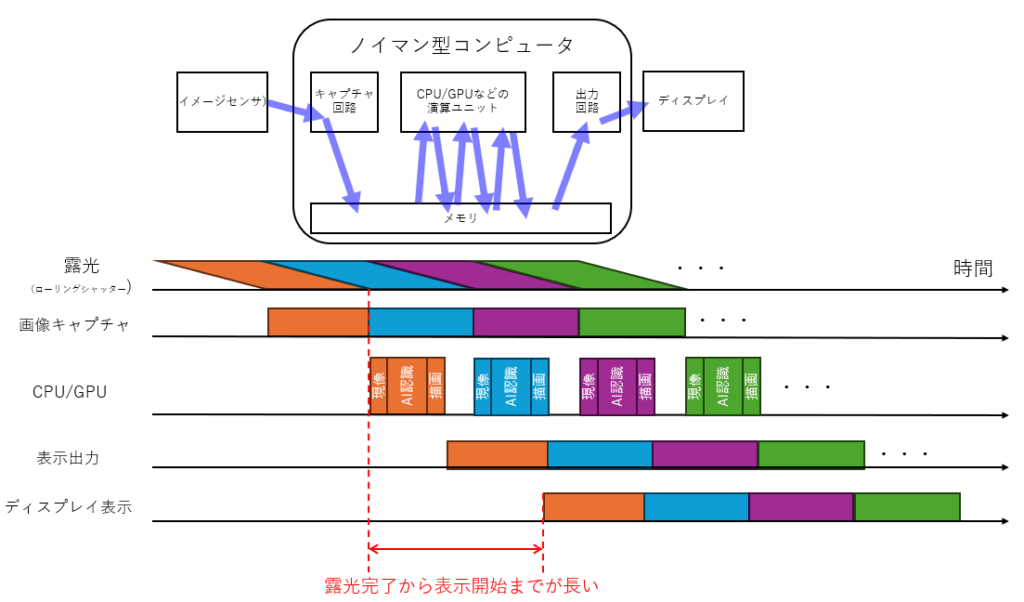
何度も持ち出す絵になりますが、わかりやすいパターンとしてCNN構造でのFPGAリアルタイム認識の絵を描きに示します。
非常に低遅延で画像処理できますし、当方はこれを1000fpsなどのハイサンプリングレートでアルゴリズム最適化しながら実施しますので、認識性能の向上と高い応答性の両立を狙っており、例えば攻殻機動隊の光学迷彩であったり、電脳コイルの電脳メガネみたいなものを実現しようとするとこれぐらいのものが必要になります。
FPGAではデバイスと演算器が同期動作できますので、カメラからフレームの最後のピクセルが読み出されるときに、そのピクセルが無いと計算できないこと以外並行して計算を先に終わらせておくといった変態じみたことが可能で、その効果が最大限出せるようにアルゴリズムと計算機アーキテクチャを組み立てます。
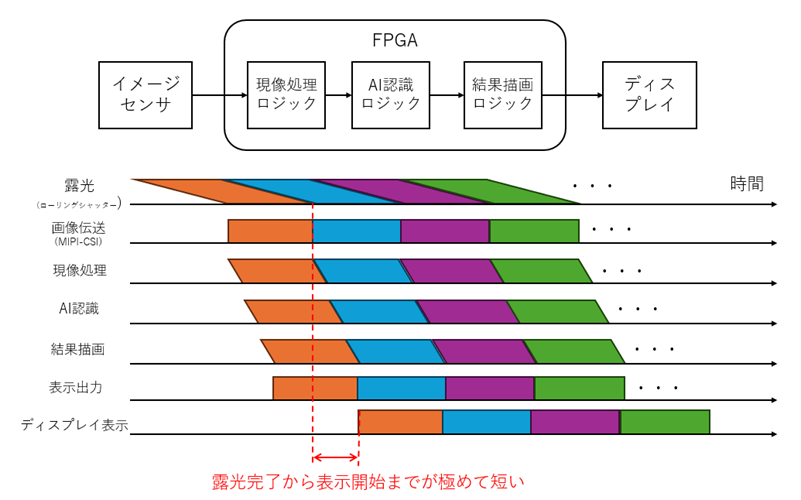
次に対局となるGPUの例を見ておきます。
まずCPUやGPUはロード/ストアアーキテクチャの宿命としてメモリにあるデータしか処理できません。加えて同期を行うにもコストがかかり、多くの場合フレーム単位などで同期します。
従って、カメラから最後のピクセルが出てきてメモリに1フレーム入ってから計算を始めるというのが基本スタイルです。
つまり、GPUが計算を始めるときには当方のFPGAはすでに計算を終えているというような事が起こります。
例えばカメラなどでセンシングする世の中のものは、動いてるものが沢山ありますので、計算している間に起る予測不能な現実世界の変化(モノの動きなど)はすべて計測誤差になります。
ようするに早く計算するだけで計測誤差が減るんですね。
そもそも交通事故を起こしてからブレーキ踏んでも間に合いませんし、そこまでいかなくとも工場などでも画像検査の為に、いちいち対象を一度固定して静止させる装置に余分なコストを掛ける事になります(なので人間に非人間的な作業をさせた方が安上がりになりがちです)。
ですので基本的に、速くではなく早く計算することにはそれ自体結構高い付加価値があるのですが、早い計算にはいろんな制約があるので、その制約の中で問題を解くアルゴリズムを考える、という事が重要で、この枠組みの中で出来る事を増やしていくというのはそれ自体に新規性があるわけです。
一方で、この枠組みの中でやってるという事の価値を正しく理解していただいてから会話をしないと「何が新規なのかさっぱりわからん」という事になりかねません。ですのでまず初見の方にはそういった説明から始めさせて頂いております。
リアルタイムAIの何が難しいのか
絶対的な演算量の問題
100倍早くする(応答時間を1/100にする)と当然ながら新規の入力から新しい出力の更新までに使える計算機パワーも 1/100 になります。これは認識率を上げるために計算量をどんどん増やしていくというGPGPUを前提としたモデル研究の真逆です。
一方で、下記で書いたような、認識対象のダイナミクスよりも高いサンプリングレートとすることで計算量低下をリカバリできるアイデアも沢山あるわけです。
これらをうまく活用できるアルゴリズムを考案して、認識率低下を補っていくという事は、低フレームレートでは出来ないことですので、高応答性を目指すが故にできるメリット、としてアルゴリズムに組み込んでいく必要がありますし、新規性のある事項になります。
一方で、ここでしばし「従来のGPUのネットより精度下がってるじゃないか、新規性なんて無いよ」という査読者に当たってリジェクトされてしまうのは非常によくある話なので、Abstract はしっかり書きましょう、という話になるわけですが。
計算機アーキテクチャの難しさ
ではハイサンプリングレートを活かして少ない演算量で精度の出るモデル(アルゴリズム)を考えればそれでいいのかと言うと全くそんなことはありません。早いコンピューティングとして実装不可能なアルゴリズムになってるケースなんてしばし見てきました。特に下手に HLS(高位合成言語)に走った学生などに見られがちで、「それGPUで実行したほうが早い(応答性)し速い(スループット)よ」というものを、成果として自信満々に出してくる学生さんもしばしいらっしゃいます。
要するに計算機アーキテクチャを十分に理解してないまま、PyTorch や HLS の掌の上で踊らされながら、FPGA を活用した凄い研究をやってる気になってしまうというパターンです。
まあ、実利として言えば PyTorch が使えて HLS が使えれば、欲しい企業さんはそれなりに居そうな気もするわけですが、アカデミック分野でとなるとそれでは成果にならないわけです。
このあたりは「なんで就職せずに院やドクターに行くの?」という話にも繋がってくるのですが、学位を取ろうとされてる以上は研究観点での価値もちゃんと示さないなとダメなのではないかとは思うわけです。
(まあ、そういう私は研究者になりたいわけではなく早くエンジニアになりたかったクチなので、学士しか持ってないのですが、この歳になって修士や博士を取りたいという人のお手伝いをする機会を頂くという得難い経験をさせて頂いていたりするわけですが)
並列性に時間軸が入る難しさ
GPUなどの Memory-to-Memory の並列計算機であれば、アルゴリズムに計算種類や計算順序や計算タイミングなどは(FPGAと比べれば)あまり考えなくてよいです。とにかく命令キューに演算が積まれていれば空いてるプロセッサが次にやらなきゃいけない計算を割り当てて消化してくれます。
一方で、FPGAでのリアルタイムコンピューティングでは、現実世界と繋ぐ外部デバイスと同期したパイプライン演算が基本となってきますので
- データがどのような順で入ってくるか
- 出力までのクリティカルパスはどこか?
- どういう演算器を何個どのように配置するか
- 矛盾なくデータが流れ/演算器は十分に稼働するか
- データ分配や供給は破綻しないか
- メモリ容量は足りるか、転送は間に合うか
などなどの事を、タイミングチャート上でしっかりと思い浮かべながら、データフローとアルゴリズムを考えていく必要があります。
跡えば ResNet など残差ネット1つとっても、後で足しこむためのオリジナルを畳み込み計算している間に遅らせて届けるパスでリソース消費する、などの基本的なことを織り込んで考えられるア頭にしておく必要があります。
よくある失敗例として
- 例えば輝度平均と分散での正規化のような、フレームが全部そろわないと計算できないような処理をたくさん含めてしまう。
- リアルタイム処理しようとすると、すさまじい規模のクロスバースイッチ(マルチプレクサ)が生成されるようなコードになっている(ノイマン型のランダムアクセスがそのままできると思っている)
- 殆ど稼働しない演算器で埋め尽くしてしまう。例えばフレームの最後に一回1サイクルしか動かないところに巨大な行列ソルバーがいたりする
- 不必要に高精度で計算してしまう
などなど、「それGPUでやった方がいいよね」な、ストリーム処理できないアルゴリズムを書きがちです。
しかしこういう処理を含むコードでも、HLSに掛けるとCPUのような動きをするコアとして合成してしまうものだから、合成結果のリソース量だけ見て「FPGAに収まる新しいアルゴリズムが出来ました」と持ってきてしまったりしちゃうわけです。
そうなると、残念ながらGPUで実行したほう、早い速いし、従来のアルゴの方が精度がいい、とかで、何一つメリットがないなんてことになりかねないのです(せっかく新規性のある土俵を用意してたはずなのに、土俵の外で戦ってしまっていたと)。
改善方法としては
- フレームグローバルな処理は前のフレームの結果からの予測で代替する
- 入力画像のデータ順序を常に意識て前方参照しない方法を考える
- ハードウェアリソース規模を常に意識して演算量を見積もりつつ常に処理パイプラインを念頭に置いておく。
- ハードウェアコストが減るように数式を組み替えたり、パラメータを統合したりする。
- 精度低下を許容してでも、ハードウェアに優しい処理順序に組み替えることを考える
- ハードウェアコストの低い演算に置き換える/ハードウェアに優しい近似方法を考える
- 現実世界で本当に必要な精度を検討する
などなど、いろんな考え方が必要になります。
DDR4-SDRAMやカメラなど外部デバイス利用の難しさ
タイミング設計をしたり、計算精度を考えたりするときに、例えばカメラの感度だとか露光タイミングだとかSNRだとか、SDRAMの転送特性だとかデータ帯域だとか、これらをちゃんと把握しておかないと適切な設計は難しいです。
(逆にこの辺りは「カメラの特性に合わせて、各層の演算精度を INT1~INT16 まで細かく最適化する研究」みたいな新規性幾らでも出てきそうな分野なんですが、案外学生には人気なかったりもしますw)
特に SDRAM って結構罠でして、ありものIPを理解して使うにしても、AXI 仕様の概要ぐらいは知っておくべきですし、計算したいタイミングに合わせてデータ持ってこないといけません。
無駄に要求してもバスが詰まってシステムデッドロックしますし、不足すると間に合いませんし、良くも悪くも FIFOバッファとかクロックの載せ替えとか出てくるので、案外最低限必要なものの準備が大変です。なによりシミュレーション環境作る難易度が一気に上がります。
授業で icarus verilog でちょろっとシミュレーションしてレポート書いてただけのレベルだと、SDRAMを含んだシミュレーション環境作るだけでも一苦労かと思います。
このあたりはLEDチカチカから初めて、地道に「なんでもいいから動くシステムを作ってみる」を繰り返さないと身につかないところはあるので実践的ではあれど、なかなかハードルが高いところには思います。
特にアルゴリズム設計でデータパスをあれこれ考察する場合、実装可能で破綻しないメモリアクセス機構を組めるかどうかは意識しておかないといけないところです。
またカメラなんかのデバイスも、動的にROI(切り出し範囲)を変えたり、シャッタータイミングを変えたり、アルゴリズムと連携した制御、つまりはアクティブセンシング的な要素を入れていくとこれはこれで研究余地増えるんですが、ここもなかなかハードルが高いようですね。
AIモデル設計の難しさ
「リアルタイムアーキテクで実装可能なアルゴリズム」でありさえすれば、実際に実装までしなくとも十分な研究成果だとは思います。
なので、「AIやっていてFPGAに興味がある」という学生さんにはそちらをお勧めするのですが、出発点として「何が実装可能なアルゴリズムなのか?」が判断できることが重要です。
そのうえで設計するのであれば PyTorch などで研究しても全く問題ないわけです。
一方で発生することとして
- INT1/2/4/8, FP16/32 などGPUが得意な精度以外を多用することになる(補償するコードを沢山挟むことになる)
- PyTorch で用意されてない演算をベタ書きすることも増える
- 前のフレームを活用しようとするとリカレント構造になりがちなのでどうやって学習させるか悩むことになる
- 学習データの準備も特殊なものを自分で用意したり加工することになる
などになります。LUT-Netなんか最たる例ですが、PyTorchでGPUを使いながらあえて、GPUに苦手なモデルを学習させるという一見非効率なことをやることになるので、きちんとした理解のもと取り組む必要があります。
ちなみにリカレント構造はやはり難しいのでBPTTやそれ以外の学習方法を考えるとか、DNN自体はCNNなどに留めてい置いて、前後にルールベースアルゴリズムの拡張をする手もあります。
画像には向かない気はしています、リザバーコンピューティングなどもその一種でしょう。
このあたりもしっかりと自分が何をやってるのか理解して取り組まないと、
- 気づかないうちに想定以上の精度で計算してしまっていた
- 現実性のないデータセットを用意してし待っていた
- 学習が一向に進まない。GPUメモリが足りずに途方に暮れる
なんてことになりかねないわけです。
おわりに
まあなんか、ぐだぐだと駄文を書いてしまったのですが、ルールベースのリアルタイムコンピューティングだけなら案外誤解は起こりにくかったことが、AIを持ち込んだとたんに迷走する人が増えているように思います。
折角FPGAという他人とは違うものを使って差をつけようとしているわけですから
- GPUではなくFPGAを使う利点をどこに出そうとしているのか?
- それは何を評価すれば実証したことになるのか?
- それは本当にFPGAで実現可能か?
- 自分が実証したいことを証明するミニマムな構成とは何なのか?
- どうすれば自分のやっていることがGPUとは違う価値を持つことを簡潔に説明できるか?
など、どんな研究においてもいえる基本的なところを押さえてから取り組んで、是非是非高い成果を出してほしいと思うわけです。


コメント